笔记|大模型训练(四)Zero Redundancy Optimizer (ZeRO)
本学习笔记是对 nanotron/ultrascale-playbook 的学习记录,该书涵盖分布式训练、并行技术以及一些优化策略。本文章是该系列笔记的第四篇,对应原书 Data Parallelism 一章的后半部分。
在前一篇文章中我们介绍了一系列与数据并行共同使用的训练优化策略,本篇我们将介绍 DeepSpeed ZeRO,这是一种旨在减少大语言模型训练中内存冗余的优化技术。
尽管数据并行可以有效扩展训练的规模,但是在每个 DP 进程上简单地复制优化器的状态、梯度以及参数会带来严重的内存冗余。ZeRO 通过在数据并行维度上对优化器的状态、梯度以及参数进行分片,来消除这种冗余,同时仍然允许计算使用完整的参数。
这种方法可以分为三种优化级别:
- ZeRO-1:对优化器状态进行分片
- ZeRO-2:对优化器状态以及梯度进行分片
- ZeRO-3:对优化器状态、梯度以及模型参数进行分片
注意,上述的「分片」指的是沿 DP 的维度进行分片,因为 ZeRO 是一种数据并行方法。除了沿 DP 的维度进行分片外,在后续的文章中也会介绍一些沿其他维度进行分片的方法。
另外值得注意的是,激活值并不进行分片,因为每个 DP 进程接收到的数据都各不相同,因此每个进程中的激活值也不同。所以这些激活值无法被复制,也就不能被分片。
下面我们来分析一下不同的优化级别分别可以节约多少内存。
回顾内存使用情况
在前面的文章中,我们已经讨论了标准的训练中优化器状态、梯度以及模型参数的内存使用情况。若使用 \(\Psi\) 来表示模型的参数量,在使用 Adam 优化器进行混合精度训练时,需要存储的每个部分的内存使用量为:
- 模型的参数(半精度):\(2\Psi\)
- 模型的梯度(半精度):\(2\Psi\)
- 模型参数和优化器状态(全精度):\(4\Psi+(4\Psi+4\Psi)=12\Psi\)
- 模型梯度(全精度,非必须):\(4\Psi\)
如果不使用全精度来累积梯度,那么总内存消耗量为 \(2\Psi+2\Psi+12\Psi\),如果使用则为 \(2\Psi+6\Psi+12\Psi\)。为了简单起见,这里我们只考虑前一种情况,不考虑全精度梯度累积的情况。
ZeRO 的思想是将上述的对象在 DP 进程之间进行分片,每个节点只存储这些对象的一部分,然后在需要的时候使用分片对这些对象进行重构,从而降低内存使用量,如下图所示。在这里,\(\Psi\) 表示模型的参数量,\(k\) 表示优化器状态的内存使用量系数(如上述的讨论,对于 Adam 来说 \(k=12\)),\(N_d\) 表示 DP 的并行进程数量:
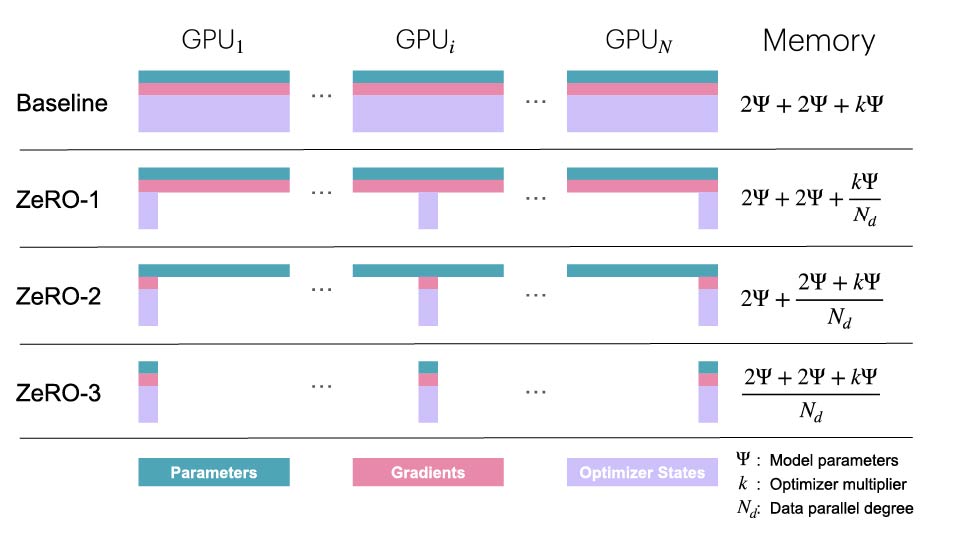
ZeRO-1: 优化器状态分片
在原生 DP 中,所有的进程在反向传播之后都需要收集全部梯度,并且同时执行相同的优化器步骤。也就是说,所有的进程都以相同的方式使用优化器对参数进行了全量更新,这显然是冗余的操作。
在 ZeRO-1 中,优化器的状态被分为了 \(N_d\) 个相同的部分,其中 \(N_d\) 是 DP 的并行度。也就是说,在 DP 的每个进程中,只维护了 \(1/N_d\) 的优化器状态,并且在优化过程中只更新 \(1/N_d\) 的 fp32 权重。
然而,模型参数需要完整更新才能进行下一轮前向传播。因此,在每个优化器步骤之后,需要增加一个额外的 all-gather 操作,使每个进程都拥有完整的更新后模型权重。这便是上图中的 \(2\Psi+2\Psi+k\Psi/N_d\) 这一公式的由来。
总结来说,ZeRO-1 每一轮训练的操作为:
- 在每个进程上使用相同且完整的 BF16 参数,但使用不同的 micro-batch 进行前向传播;
- 在每个进程上使用相同且完整的梯度,但使用不同的 micro-batch 进行反向传播;
- 对梯度进行 reduce-scatter 操作;
- 对每个进程本地的优化器状态(也就是完整优化器状态的 \(1/N_d\))进行优化,得到完整的全精度参数,然后将其转为半精度参数;
- 对半精度参数进行 all-gather,使每个进程都得到完整的更新后模型参数。
整个过程如下所示:
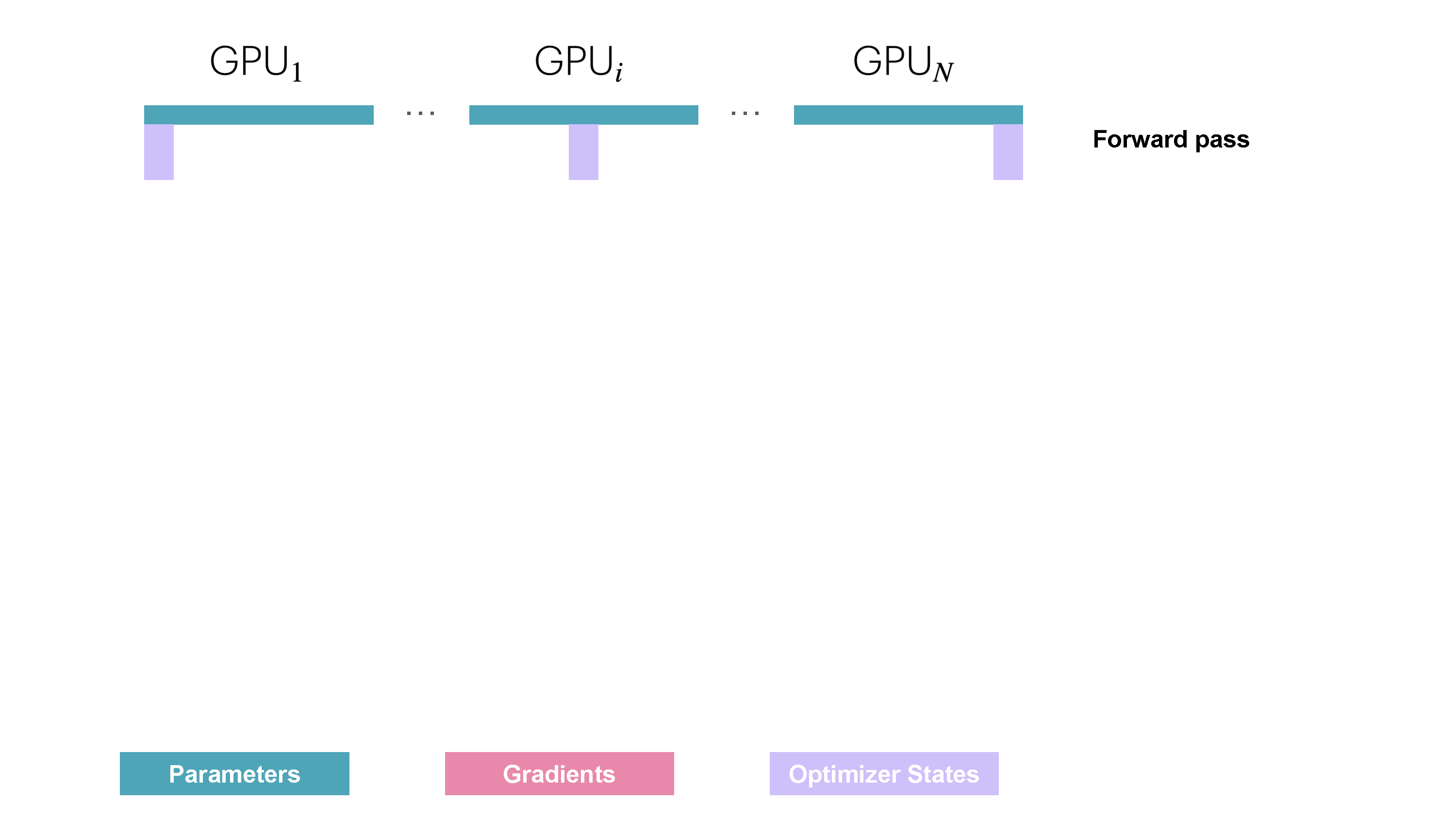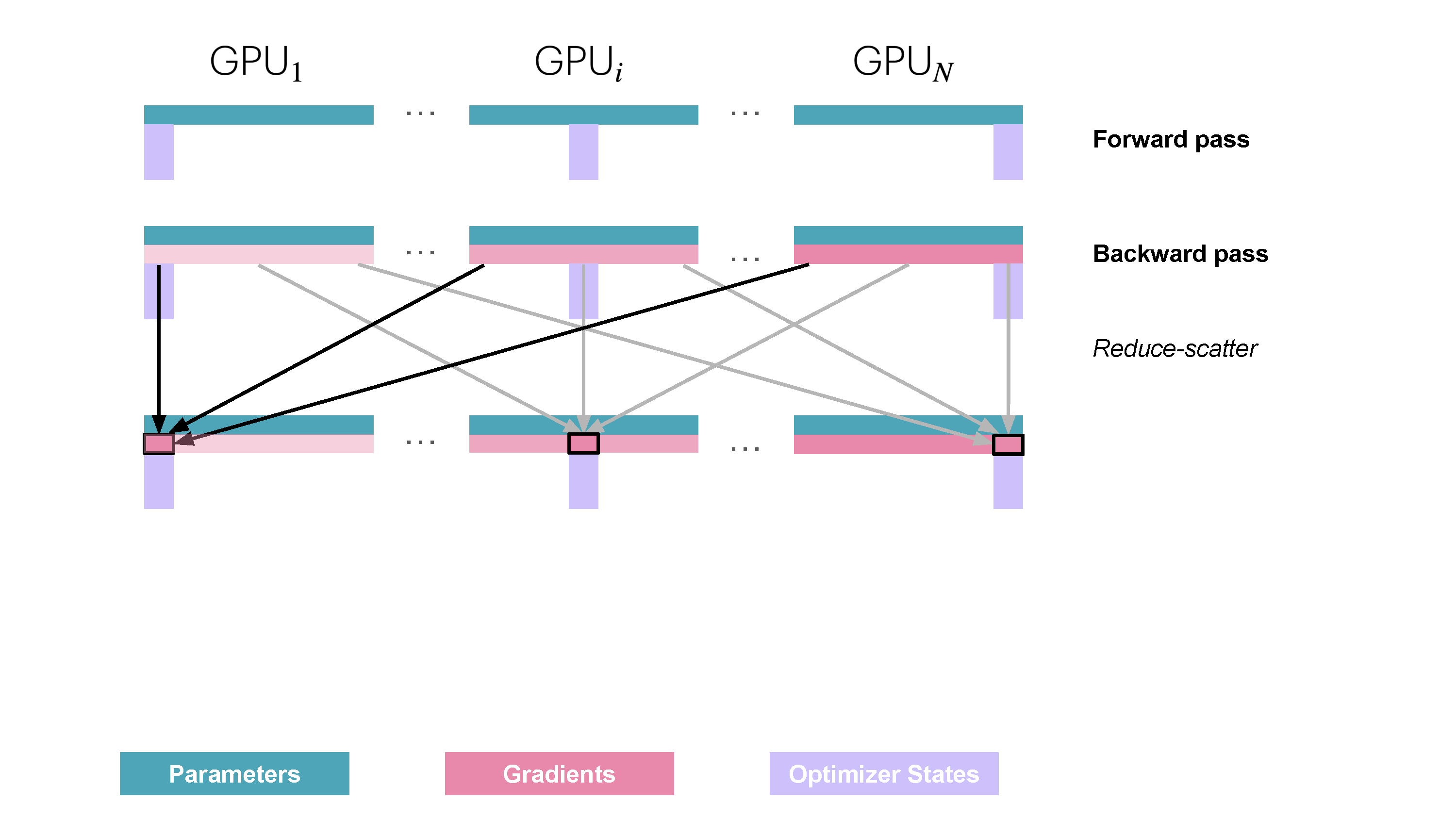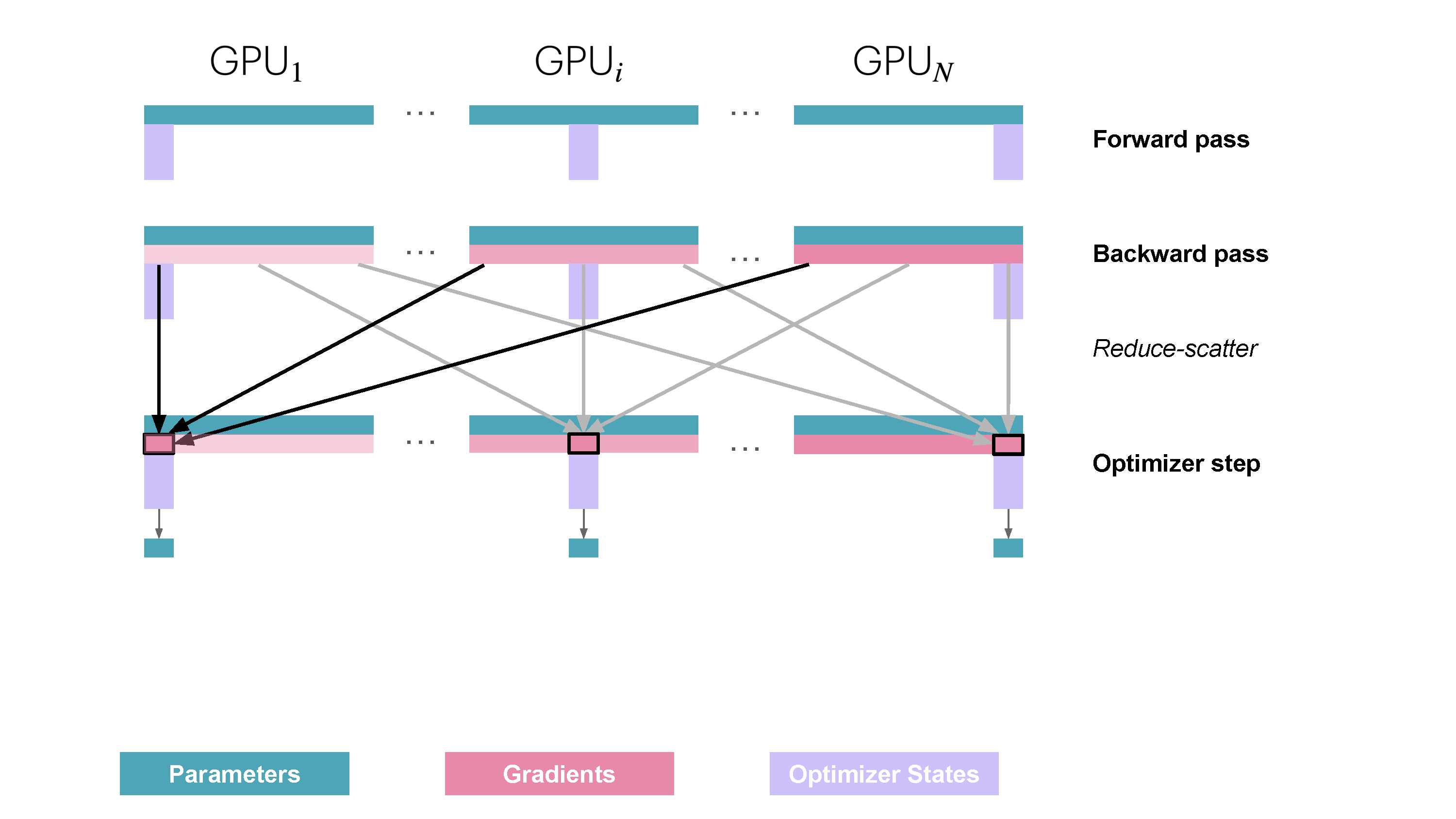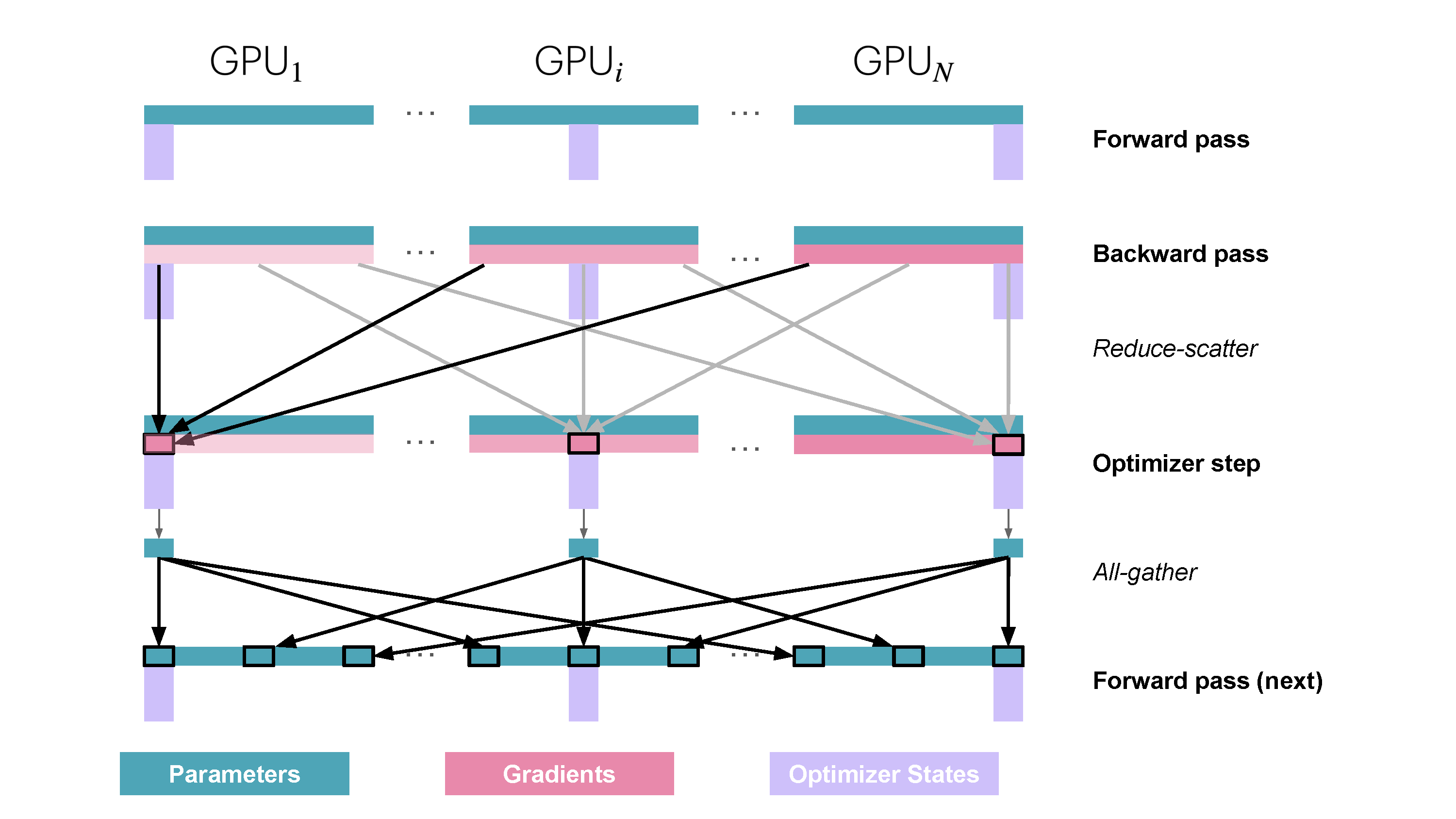
从通信的角度来说,ZeRO-1 相比普通的 DP,将 all-reduce 改成了 reduce-scatter 操作,并且在优化器步骤之后增加了一步 all-reduce 的操作,如下图所示:

和前一篇文章中对 DP 的讨论类似,这里的进程间通信过程也可以和其他的步骤重叠,来提高效率。其中 reduce-scatter 可以和反向传播过程重叠,这是比较显然的。而 all-gather 操作则主要有两种策略:
- 和优化器步骤重叠:在优化器更新第一部分参数后立即启动 all-gather;
- 和下一轮前向传播重叠:将每一层参数的 all-gather 和前向传播重叠
上述的技术在实现方面比较复杂,需要使用复杂的钩子函数和分桶机制。在实际使用时,可以直接使用 Pytorch 的原生 ZeRO-3 或者 FSDP 实现,并将 FSDPUnit 设置为整个模型。
ZeRO-2: 加入梯度分片
与 ZeRO-1 同理,我们可以模仿对优化器状态分片的方式,同样对梯度也进行分片。然后在反向传播期间,不再对梯度执行 all-reduce,而是只执行 reduce-scatter 操作。这样,我们在内存中只需要存储所需梯度的 \(1/N_d\),从而在 ZeRO-1 的基础上节约更多内存。ZeRO-2 的流程如下图所示:
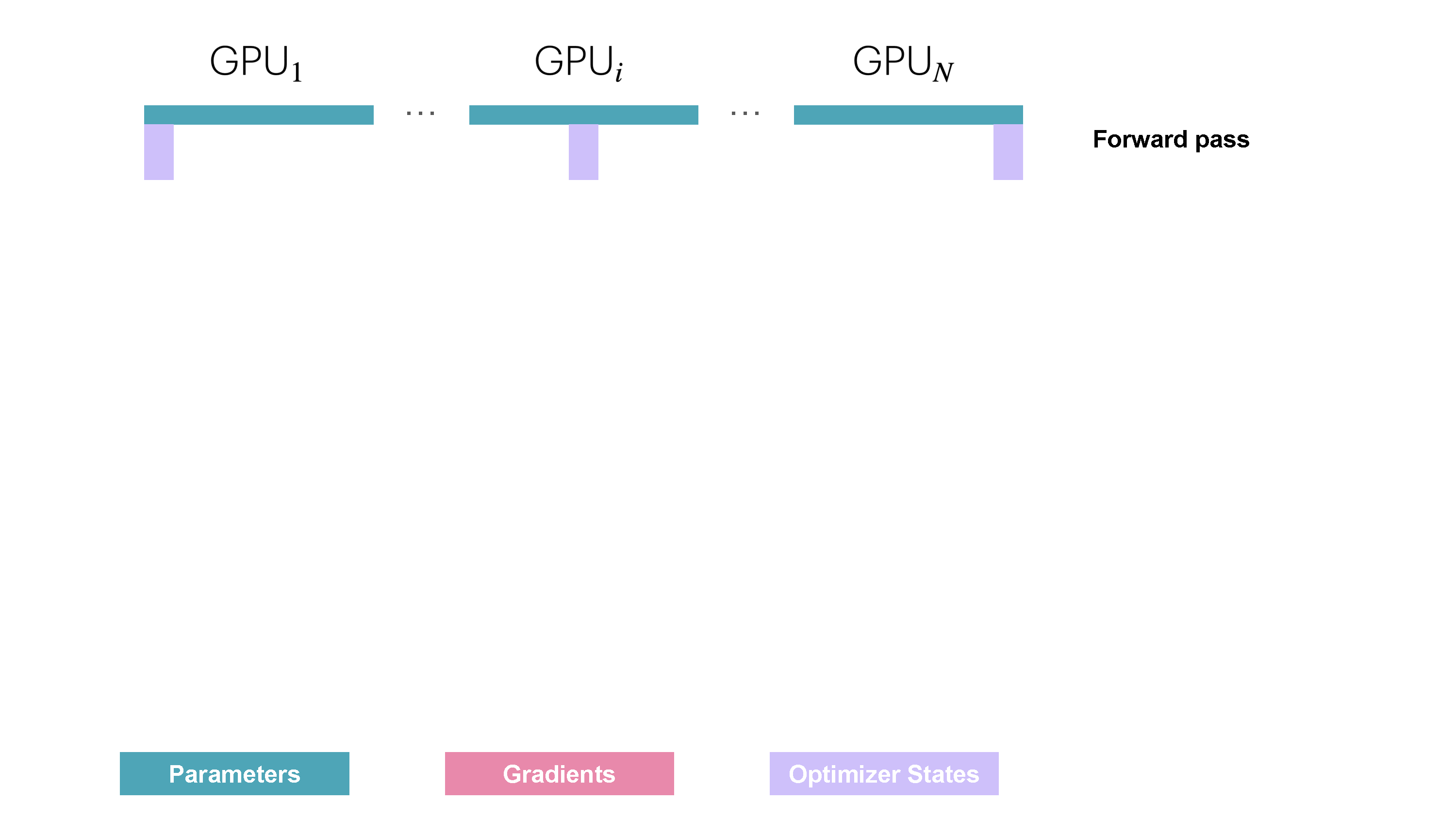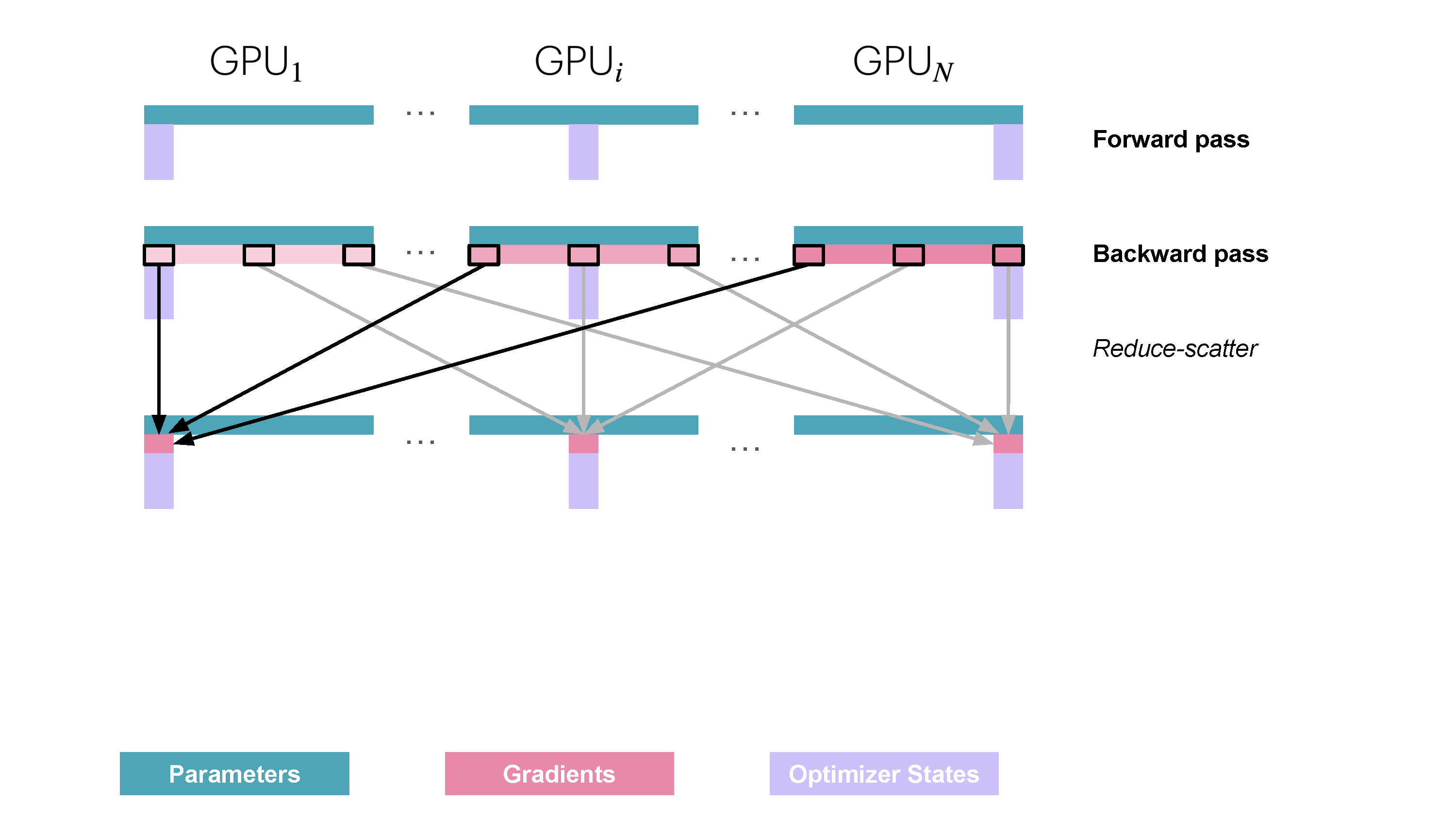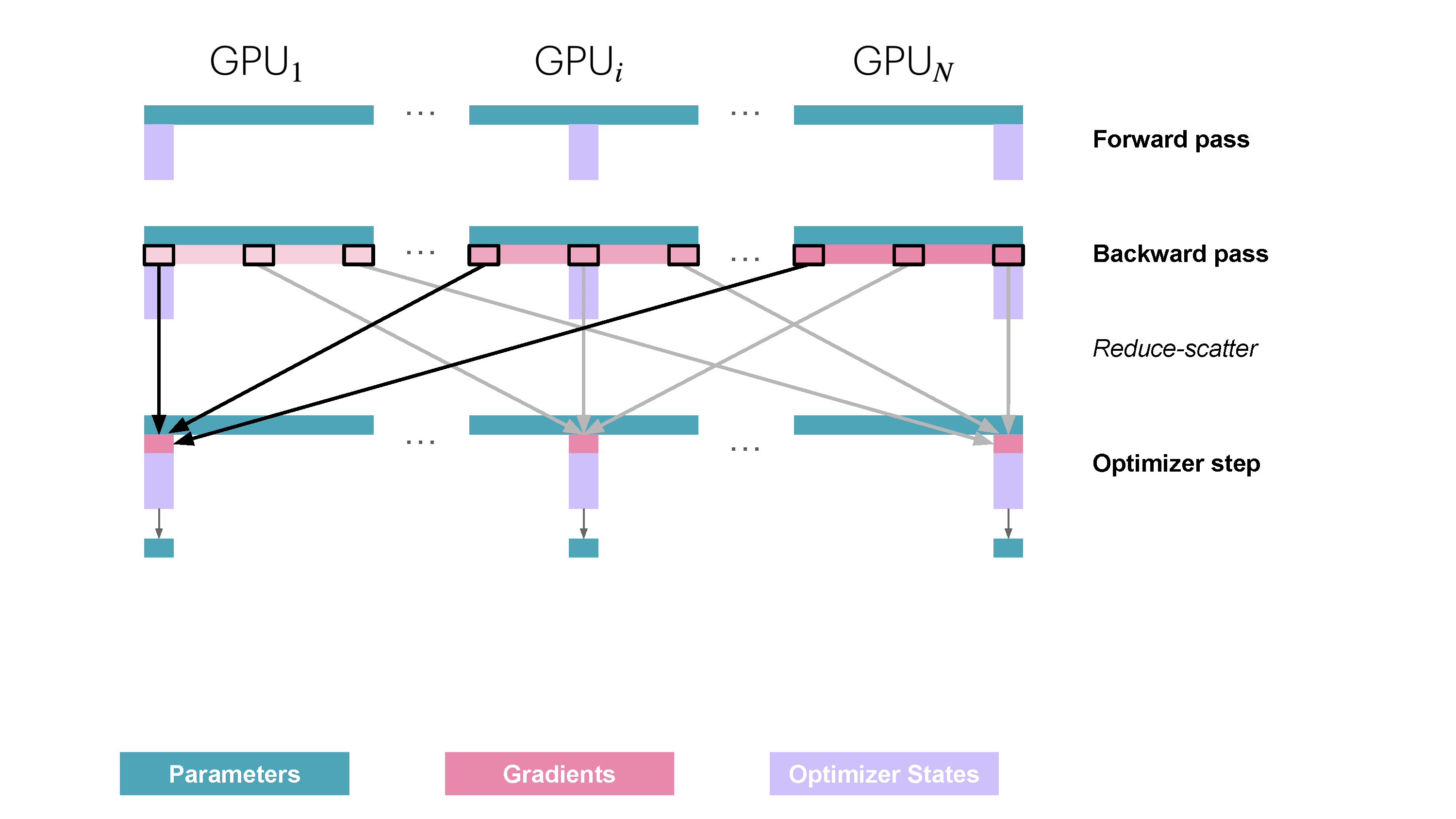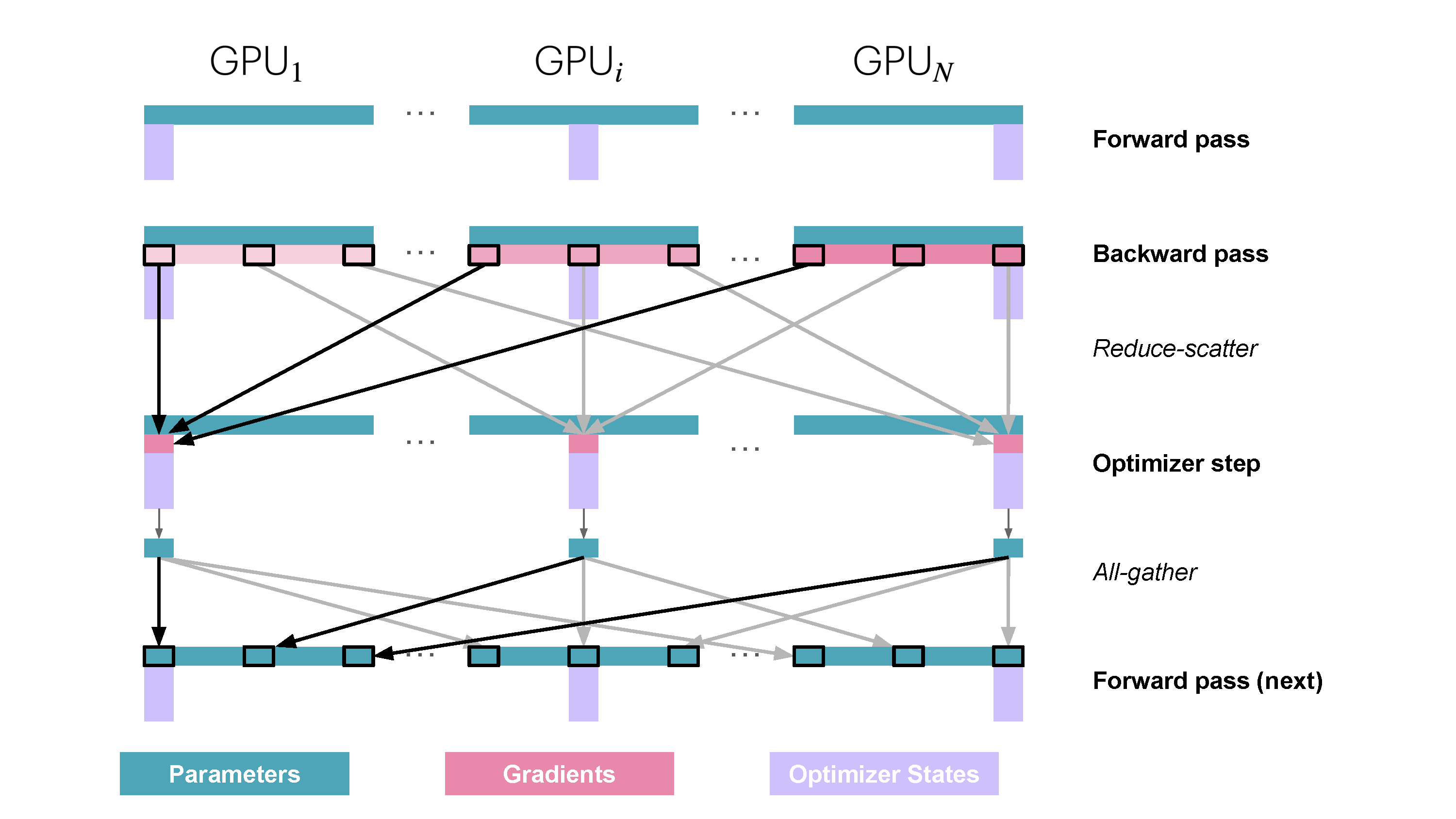
在通信方面,ZeRO-2 的进程间通信过程也与 ZeRO-1 相同,只不过是需要在 reduce-scatter 之后把多余的梯度内存释放掉。比较 ZeRO-2 和 ZeRO-1,可以发现 ZeRO-2 相比 ZeRO-1 并没有引入额外的开销,但前者的内存占用量更小,因此通常相比 ZeRO-1 来说,ZeRO-2 是更好的选择。
ZeRO-3: 加入模型参数分片 (FSDP)
在上述 ZeRO-2 的基础上再加入模型参数分片,就得到了 ZeRO-3。在 Pytorch 中,ZeRO-3 的原生实现被称为 FSDP,也就是 Fully Sharded Data Parallelism,完全分片数据并行。
现在模型参数也变成了分布式的,那么在实际的前向传播和反向传播过程中,模型的参数需要在使用时进行收集,在前向传播中的情况如下图所示。在每一层进行前向传播前,需要先使用 all-gather 将所有的参数收集起来,然后在前向传播结束之后将参数的内存释放:
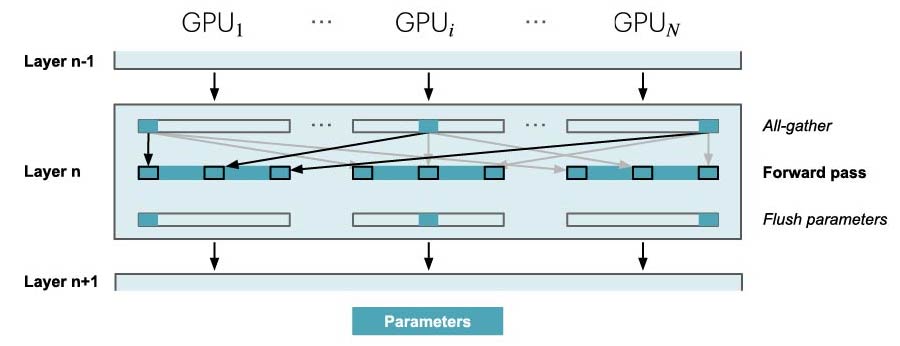
对于反向传播也是一样,只不过是方向相反:
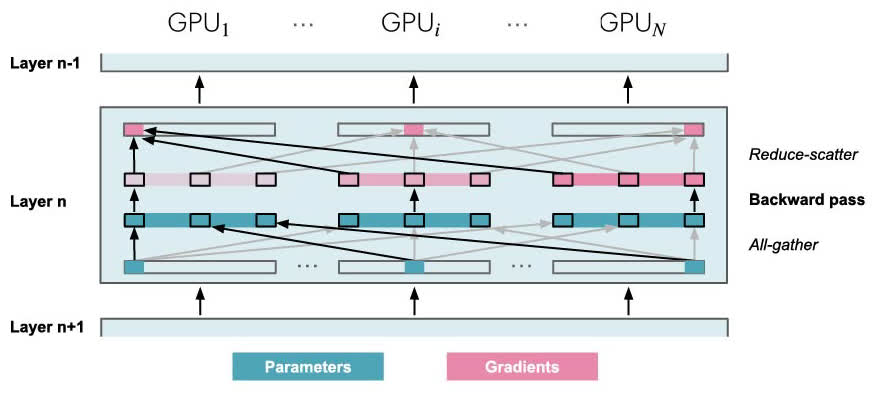
因为需要在前向传播和反向传播的过程中进行参数同步,因此在一个训练步骤中比 ZeRO-2 多了 \(2\cdot\text{num\_layers}-1\) 次额外的 all-gather 操作,每次操作都会引入一个小的基础延迟开销:

在 ZeRO-3 中,前向传播和反向传播时需要分别进行一次 all-gather 操作,通信开销是 \(\Psi+\Psi\)。在最后还需要进行一次和 ZeRO-2 相同的 reduce-scatter 来处理梯度,共产生 \(3\Psi\) 的通信开销,与此相比,ZeRO-2 的通信开销是 \(2\Psi\)。
为了尽可能提高训练效率,在实际场景中我们可以通过 prefetching 的方式将下一层的参数同步与本层的前向传播同时进行;同样在反向传播时,提前同步前一层的参数。不过需要注意的是,随着 DP 并行度的提高,所需的通信带宽会逐渐升高,因此随着 DP 规模的增大,这种策略也会逐渐生效。(从经验上来说,DP 的并行度不应该超过 512)
从内存的角度来说,我们最终的内存占用为 \((2\Psi+2\Psi+k\Psi)/N_d\),也就是说从理论上来说,如果我们一直增加 DP 的并行度,就可以无限地降低内存占用(至少对于除了激活值外的部分来说是这样)。
总结来说,通过 DP,可以同时使用多个模型的副本进行训练,从而显著提高训练的吞吐量。而通过 ZeRO,可以将参数、梯度和优化器状态在进程间进行分片,从而训练无法放入单个 GPU 的模型。
关于 FSDP1、FSDP2 以及一些实现相关的复杂情况,可以参考这篇文章中的讨论。
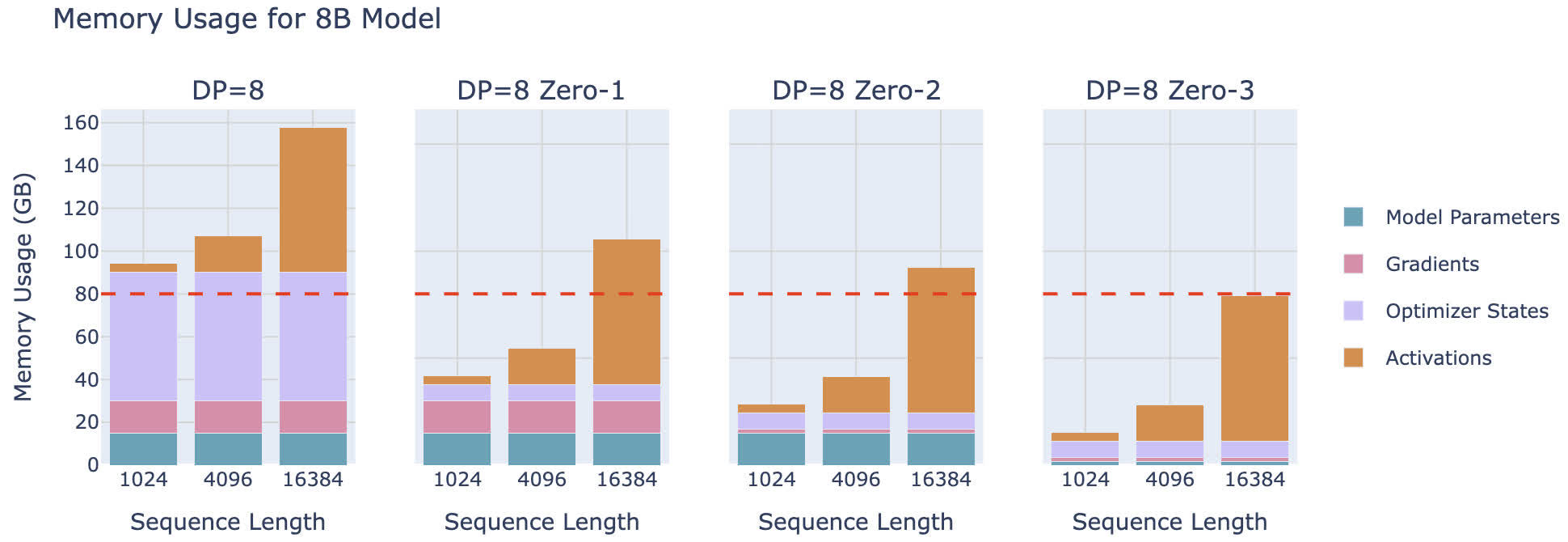
尽管 ZeRO 看上去已经有了很高的并行度,但依然存在一些限制:ZeRO 无法对激活内存进行分片。由于激活内存会随着序列的长度和 batch 的大小而增加,所以有时我们只能用很短的序列进行训练。如下图所示是使用不同级别的 ZeRO 进行训练时的显存占用,可以发现即使使用 ZeRO-3,当序列长度达到 16k 的时候,占用显存也已经达到了 80 GiB:
为了解决这个问题,需要引入一种新的并行维度——张量并行,也就是 Tensor Parallelism (TP)。这种并行维度除了能在设备间分片参数、梯度、优化器状态,也能分片激活值,我们将在下一篇文章中进行学习。