笔记|大模型训练(三)数据并行与相关优化策略
本学习笔记是对 nanotron/ultrascale-playbook 的学习记录,该书涵盖分布式训练、并行技术以及一些优化策略。本文章是该系列笔记的第三篇,对应原书 Data Parallelism 一章的前半部分。
数据并行(Data Parallelism, DP)的核心思想是把模型复制到多个 GPU 上(可以把这些副本称为模型实例),并在每个 GPU 上并行地对不同的 micro-batch 进行前向和反向传播——这也是「数据并行」这个名称的来源。尽管这个方法已经非常常见,但在本节中我们将会更深入地探讨这一内容。
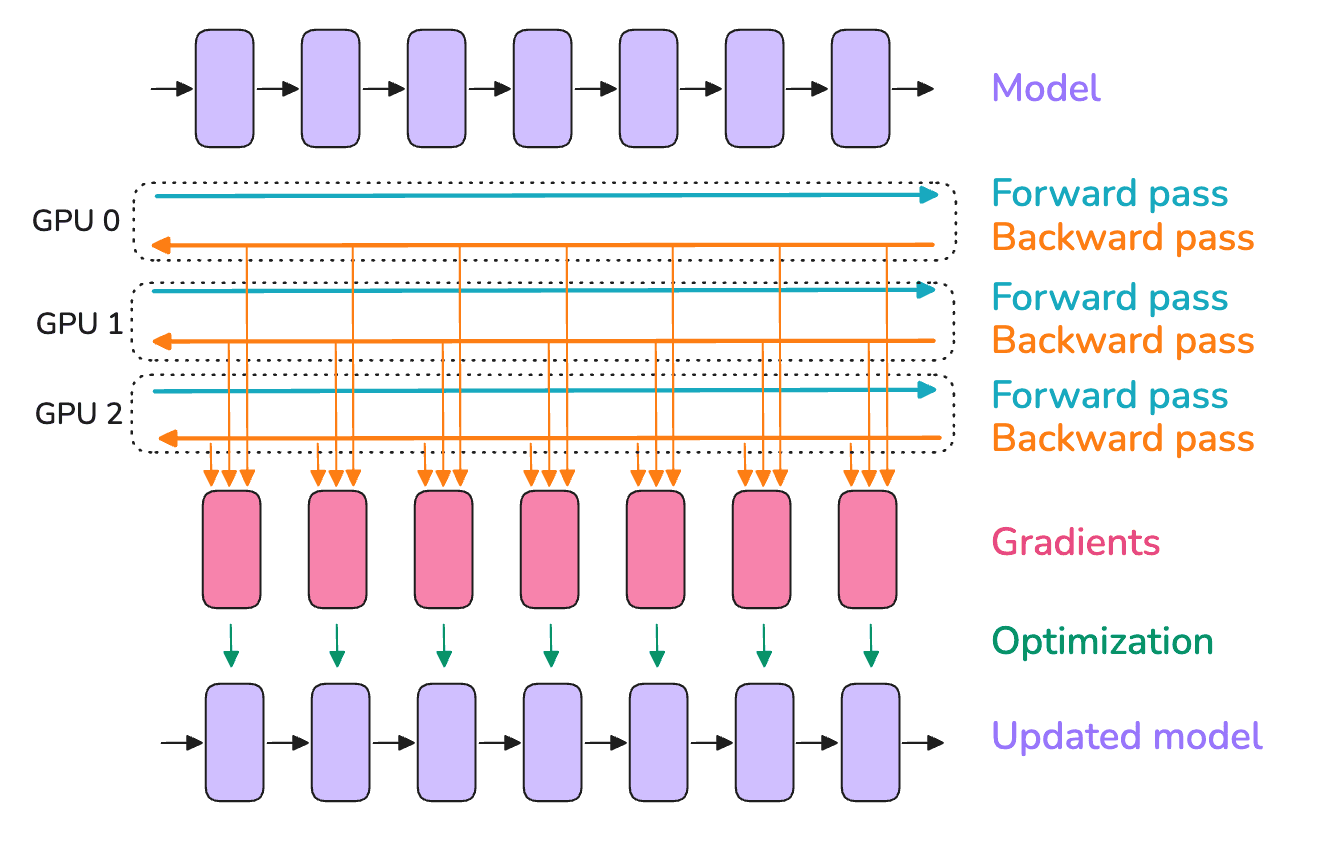
在每个 GPU 上使用不同的 micro-batch 意味着每个 GPU 上的梯度也各不相同。因此,为了保证不同 GPU 上的模型实例相互同步,我们需要使用 all-reduce 操作来平均来自所有模型实例的梯度。这个操作发生在反向传播期间、优化器执行更新之前。
一个朴素的数据并行实现会等待反向传播完成后获得所有的梯度,然后对所有的 DP 节点出发一次 all-reduce 来同步梯度。但这种先计算后通信的串行步骤是一个大忌,因为 GPU 在通信期间会处于空闲状态,如下图所示。
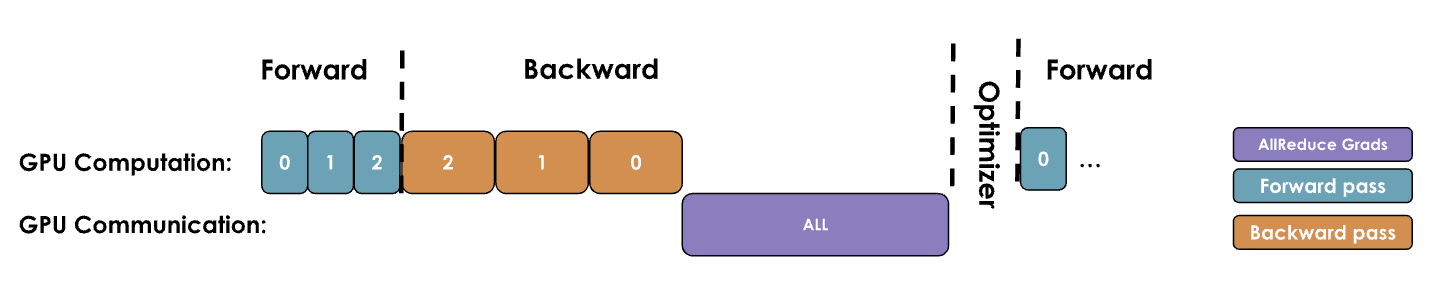
为了提高这个过程的效率,需要尽可能地让通信和计算重叠,使其能够同时进行。下面的几种优化手段就是为了这个目的而出现的。
优化一:将梯度同步过程和反向传播重叠
为了将通信重叠,一个最直接的方法就是把反向传播和梯度同步进行重叠。可以回顾一下本文最开始的示意图,梯度会一层一层地计算,如果我们不进行优化,所有的梯度同步操作都必须在所有层的梯度计算结束后再同步。但实际上每一层的梯度在刚计算出来时就可以开始同步操作,而不必等所有的梯度都计算完。这样,梯度计算和梯度同步就能同时进行,在最后一层的梯度计算完成后,很快就可以得到汇总后的梯度结果,如下图所示:
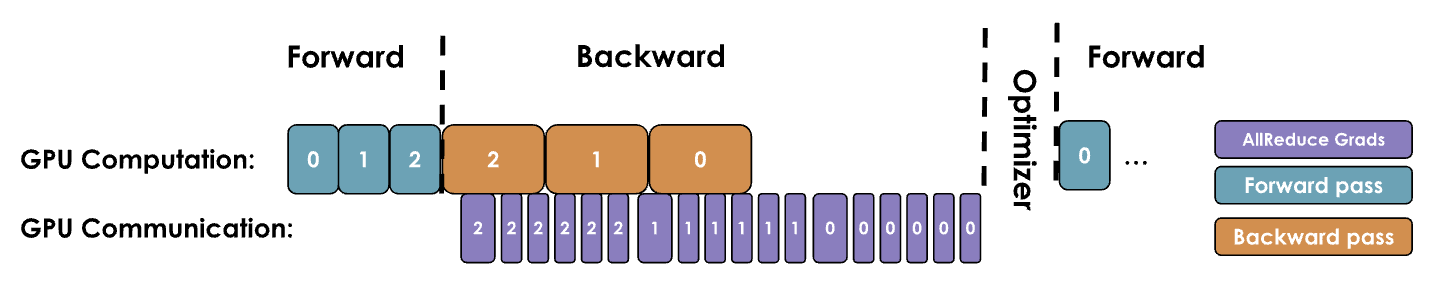
在 Pytorch 中,这个操作可以通过为每个参数附加一个 hook 函数来实现,下面给出了一个简单的示例。一旦某个参数的梯度准备就绪,这个 hook 就会马上被触发,而其他参数的梯度计算仍在继续。这样可以把大部分 all-reduce 操作和梯度计算重叠,从而提高效率。
Pytorch 实现
首先需要实现收集梯度的钩子函数,这里考虑了梯度累积的情况,如果启用了梯度累积,那么只有在梯度累积的最后一次反向传播时才需要进行梯度同步操作:
1 | def _allreduce_grads(self, grad): |
然后实现一个函数用来给所有的参数都注册 hook:
1 | def register_backward_hook(self, hook): |
最后再调用
self.register_backward_hook(self._allreduce_grads)
完成注册。
优化二:梯度分桶
GPU 操作在处理大张量时通常比在许多小张量上分别执行操作更加高效,这对通信也同样适用。因此可以将梯度分组到「桶」中,并为同一个桶内到所有梯度启动单次 all-reduce,而不是为每个梯度独立操作,如图所示:
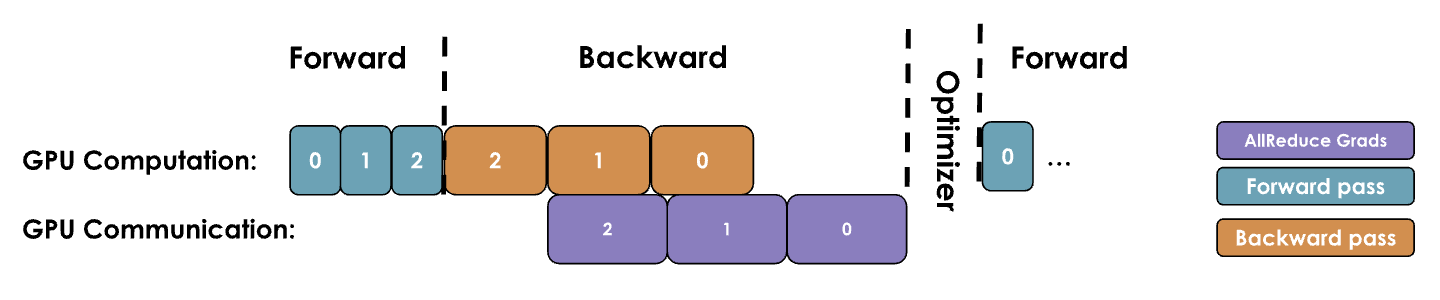
分桶的思想是比较简单的,不过实现比较复杂,可以参考下面的实现。
Pytorch 实现
为了分桶需要实现一个管理桶的类
BucketManager,关于这个类的实现可以参考 picotron
的实现。我们这里主要关注 pytorch
相关的部分,当然这部分一般不需要自己实现,精力有限的读者也可以跳过这一部分。
我们不妨先梳理一下整体的逻辑:在模型初始化的时候,我们根据每个参数的维度将所有的参数分成不同的桶。在反向传播时,如果某个参数的反向传播完成了,就先把这个参数的状态标记为「可以开始同步」。当同一个桶中的所有参数都可以开始同步时,就触发同步。在同步完成后,把接收到的梯度拷贝回应有的位置。
在 picotron 的实现中,所有的桶相关的管理都由
BucketManager 负责,而具体的同步和拷贝等操作则由 hook
触发。为此,需要首先创建这个类,以及注册相关的钩子函数:
1 | self.require_backward_grad_sync = True # 参数是否要同步梯度(为了兼容梯度累积) |
我们主要需要关注的是钩子函数的实现,这里的钩子函数是为每个参数分别创建的:
1 | def _make_param_hook(self, param: torch.nn.Parameter, bucket_manager: BucketManager): |
下面是 _post_backward 的实现:
1 | def _post_backward(self): |
注意:在执行通信操作时,张量在内存中必须是连续的,以避免冗余的内存拷贝。为了优化这一点,我们通常会预先分配与激活值或模型参数大小相同的连续缓冲区,专门用于通信。这虽然加快了通信速度,但也部分导致了训练期间的峰值内存使用。
优化三:与梯度累积共同使用
梯度累积在执行 optimizer.step()
更新参数前执行多次前向和反向传播,当使用梯度累积时,需要谨慎选择何时同步梯度。在最普通的实现中,每次反向传播都会触发一次
all-reduce
操作,这是不必要的,因为只需要在最后同步一次梯度,也能达到相同的效果。在这里可以回顾一下上一小节中的代码实现,在梯度累积的过程中是否进行梯度同步是通过
require_backward_grad_sync 这个变量控制的。
当我们同时使用数据并行和梯度累积,全局 batch size 的计算公式就变成了: \[ bs=gbs=mbs\times grad\_acc\times dp \] 其中 \(grad\_acc\) 是梯度累积的步数,\(dp\) 是数据并行的实例数量。因此,给定一个目标全局 batch size 大小,我们可以用梯度累积步骤来换取数据并行节点数,以加速训练。在实际应用过程中,通常的做法是尽可能最大化数据并行规模而不是梯度累积步数,因为数据并行是天然并行的,不同于梯度累积的串行性质。当仅靠扩展数据并行还不足以达到目标全局 batch size 大小时,才需要使用梯度累积。
数据并行作为一种最常用的并行手段,被称为一维并行(后续还会有其他四个并行维度)。
关于数据并行的补充阅读材料:Data-Parallel Distributed Training of Deep Learning Models
当前内容小结
让我们来快速总结一下使用数据并行进行训练时,如何进行训练配置的设定:
- 首先通过 follow 现有工作或进行小规模实验,来确定最佳的全局 token batch size;
- 然后选择训练的序列长度,确定方式同上。一般来说,2k-8k token 的序列长度是比较合适的,不过在训练末期需要增加序列长度,加入一些更长上下文的数据样本,以得到上下文更长的模型;
- 寻找单个 GPU 上最大的 micro-batch size;
- 通过目标全局 batch size、单个 GPU 上的 micro-batch size 以及 DP rank 数量来确定梯度累积的步数。
2k-8k token 在预训练中效果良好的原因是,网络上的长文档比较罕见。具体的分析请见 In the long (context) run。
尽管数据并行能够将 all-reduce 梯度同步以及反向传播过程重叠来节约时间,但这种优势在训练规模越来越大时会逐渐失效。这是因为随着系统中增加越来越多的 GPU,它们之间的通信开销会显著增长,对网络带宽的需求会变得巨大,导致 GPU 数量增加时反而效率降低。
注意:在 512+ GPU 的规模下,通信操作将开始受到环路延迟(信号在环路中传播一次所需的时间)的影响,此时通信和反向传播过程将无法完全重叠。这会降低运行效率以及吞吐量。在这种情况下,我们应该开始探索其他维度的并行化。
这一点可以通过一些基准测试来直观地感受,如下图所示:当并行规模超过某个限制时,吞吐量开始显著下降,而每个 GPU 的内存使用量则保持不变,不受 DP rank 数量的影响。
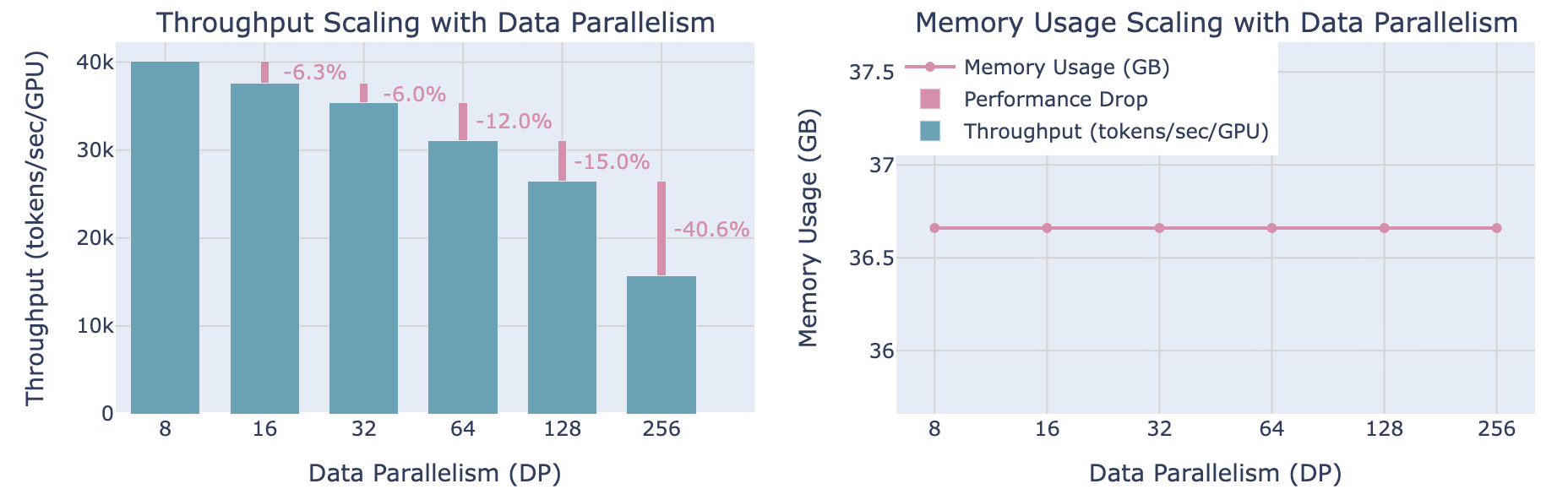
除了通信开销问题外,数据并行还有另一个无法解决的问题,也就是对于超大规模的模型或者超长的序列,单个 GPU 无法放入整个模型。为了解决这个问题,通常我们需要将一部分张量移动到 CPU 上,或者将权重/梯度/优化器状态张量在 GPU 设备间进行拆分。在拆分时,主要有两种拆分方法:并行化(张量、上下文或流水线并行)和分片(DeepSpeed ZeRO 或 PyTorch FSDP)。
由于分片的做法和数据并行更加相关,所以下一篇笔记的内容主要是关于分片的,敬请期待。