开发记录|基于 CogVideoX 实现 DDIM Inversion
近期正在基于 CogVideoX 实现一些视频编辑相关的功能,然而在尝试的时候发现了一个比较奇怪的问题:CogVideoX 无法直接使用和 Stable Diffusion 类似的方式实现 DDIM Inversion。
使用 DDIM 对扩散模型进行采样时,会形成一条「轨迹」。DDIM Inversion 就是从一条现有的视频出发,沿着这条轨迹逆向返回得到最初的噪声的过程。由于 DDIM 采样是确定性的过程,所以从这个得到的噪声出发再重新进行采样,应当能够得到原始视频;如果在采样过程中改变一些控制条件(例如修改视频描述)就可以实现对原始视频的编辑。
为了在 CogVideoX 上实现 DDIM Inversion,最初我的实现大概是这样:
1 | pipeline = CogVideoXPipeline.from_pretrained(model_path) |
简单来说就是先初始化一个和 pipeline 原始的 scheduler 参数都一样的
DDIMInverseScheduler,然后替换掉 pipeline 原始的 scheduler
进行 inversion,在 inversion 结束后再换回原本的 scheduler 进行重建。
这个过程看起来非常的合理,但是得到的结果却非常奇怪:inversion 的结果看起来是正常的——能够隐约看到一些原有视频轮廓的噪声。然而重建之后完全无法得到原始视频,在尝试了很多中不同的采样参数之后依然没有得到正确结果(至今也没有明白这个问题的原因所在)。
搜索了一下社区发现也有人遇到了类似的问题,因此大致可以排除是实现本身的问题。因此最终实现的时候参考一些最近的方法换了一种思路:既然直接用 inversion 得到的噪声无法沿原始的轨迹移动,那么如果在重建采样的过程中使用这条路径上的条件进行一些引导,应该能够迫使重建采样过程回到「正轨」。具体来说,大致的框架如下所示,在 inversion 的过程中缓存所有 attention 中的 key 和 value,然后在重建时和对应的 key、value 拼接,从而实现引导。
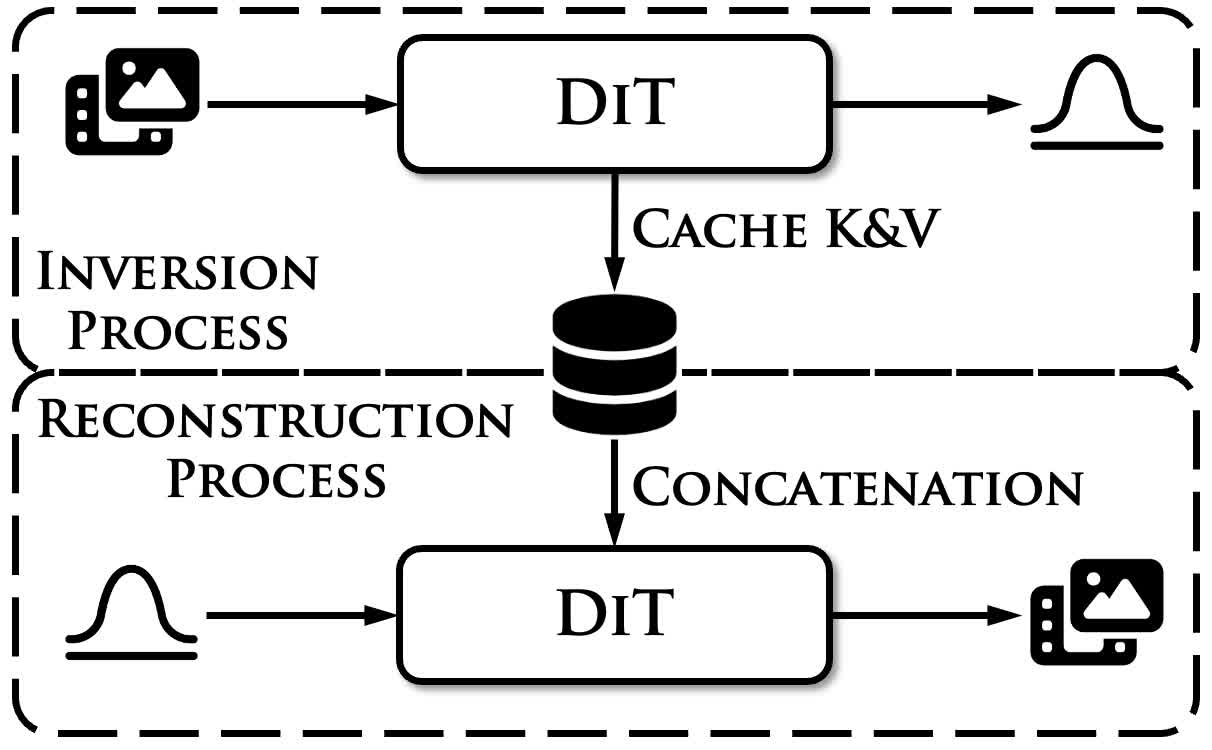
思路听起来比较简单,不过主要有几处细节需要考虑:
- 首先是资源消耗问题,以 20 帧长宽分别为 720 和 480 的视频为例,VAE
编码后的形状为
[16,5,30,45]。注意力中 embedding 为 3072 通道,共有 42 个 transformer block,如果以 bf16 精度采样 50 个时间步,那么总共需要缓存的键值为5*30*45*3072*42*2*50*2也就是 174 GiB 的大小。无论这些数据缓存在显存、内存还是硬盘中,都是极大的开销。因此,虽然目标是缓存键值,但实际实现的时候应当缓存每一个时间步的 latents,再在重建时现场算出键值。 - 其次是位置编码,为了使模型能够感知控制条件键值对中的位置信息,在键值对拼接后,每一组图像 token 都需要单独进行旋转位置编码,以保证相同位置的 token 能够对应到视频中的相同区域。
最后就是具体实现了,首先改造 pipeline 的 __call__
函数,初始化一个形状为 [T,B,C,F,H,W] 的张量用来存储轨迹上的
latents,把这条轨迹作为返回值:
1 | trajectory = torch.zeros_like(latents).unsqueeze(0).repeat(len(timesteps), 1, 1, 1, 1, 1) |
其次是为这个函数添加一个 reference_latents
的参数,如果这个参数不为 None
就表示本次调用是重建过程,需要使用传入的轨迹作为条件。由于缓存的是
latents,那么为了现场计算出 key 和 value,需要做以下几件事:首先是在
forward transformer 前将条件 latents 和 noisy latents 沿 batch
维度拼接,并将 CFG 以及 text embeddings 的 batch 维度做相应的对齐:
1 | if reference_latents is not None: |
这样处理后,latents 以及 text 的排列方式如下所示:
1 | Latents: | Recon Latents | Ref Latents | |
随后改造 attention processor,在计算注意力时将 qkv 沿 batch 维度等分为两组,第一组将第二组的键值拼接上之后计算 attention(带有控制条件的一组),第二组正常计算 attention(负责现场计算 inverse 路径上键值的一组)。实现大概如下所示:
1 | def __call__(self, some_arguments): |
最后比较关键的就是 RoPE 的部分,MMDiT 的 latents 中包括 text tokens 和 image tokens 两个部分,在应用 RoPE 的时候需要对两部分的 latents 中的 image token 分别计算 RoPE:
1 | | Text Tokens | Recon Image Tokens | Text Tokens | Ref Image Tokens | |
具体的代码实现为:
1 | if image_rotary_emb is not None: |
大体上通过这种方式就实现了 DDIM Inversion,最终的结果基本上达成了编辑的目标(不过还是出现了一些偏色以及模糊的问题):

总之这次的探索还是比较曲折的,而且为什么不能直接把 inverse latents 重建回去也依然是一个未解之谜,如果之后还有时间精力的话希望能把这个问题搞明白。