笔记|扩散模型(一六)CogVideoX 论文解读|文生视频扩散模型
CogVideoX 是智谱近期发布的视频生成模型,和上一个工作 CogVideo 不同,这个方法是基于扩散模型实现的。从框架图来看,感觉 CogVideoX 同时吸取了 Sora 和 Stable Diffusion 3 的优势,不仅使用了 3D VAE,还引入了双路 DiT 的架构。
具体来说,CogVideoX 主要进行了以下几个方面的工作:
- 使用 3D VAE 编码视频,有效地压缩视频维度、保证视频的连续性;
- 引入双路 DiT 分别对文本和视频进行编码,并用 3D attention 进行信息交换;
- 开发了一个视频标注的 pipeline,用于对视频给出准确的文本标注;
- 提出了一种渐进式训练方法和一种均匀采样方法。
CogVideoX
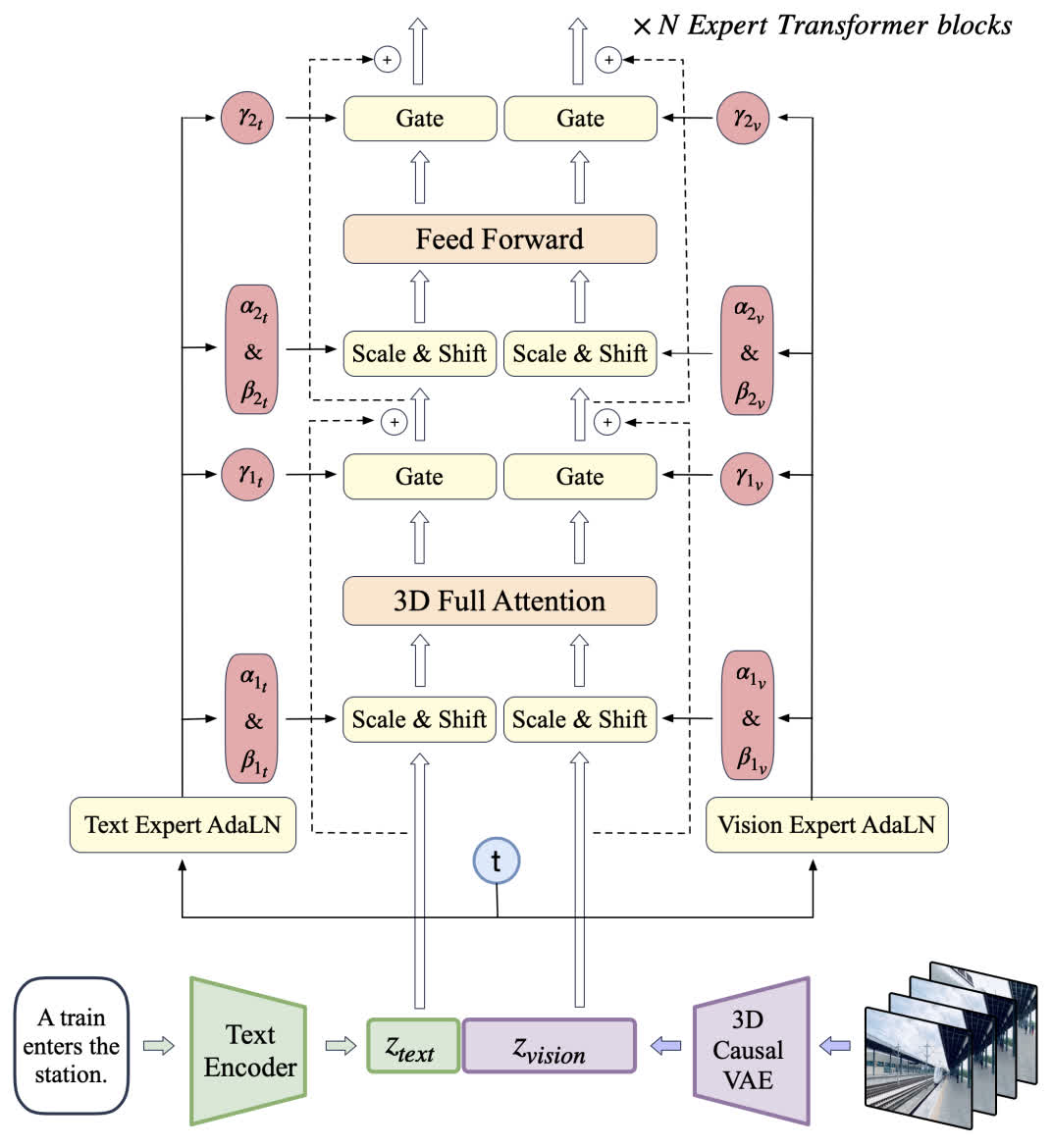
CogVideoX 的整体架构如下图所示,文本和视频分别经过文本编码器(这里是 T5)和 3D VAE 编码后输入主干网络。文本和视频分别经过一条支路,并在注意力部分进行交互。
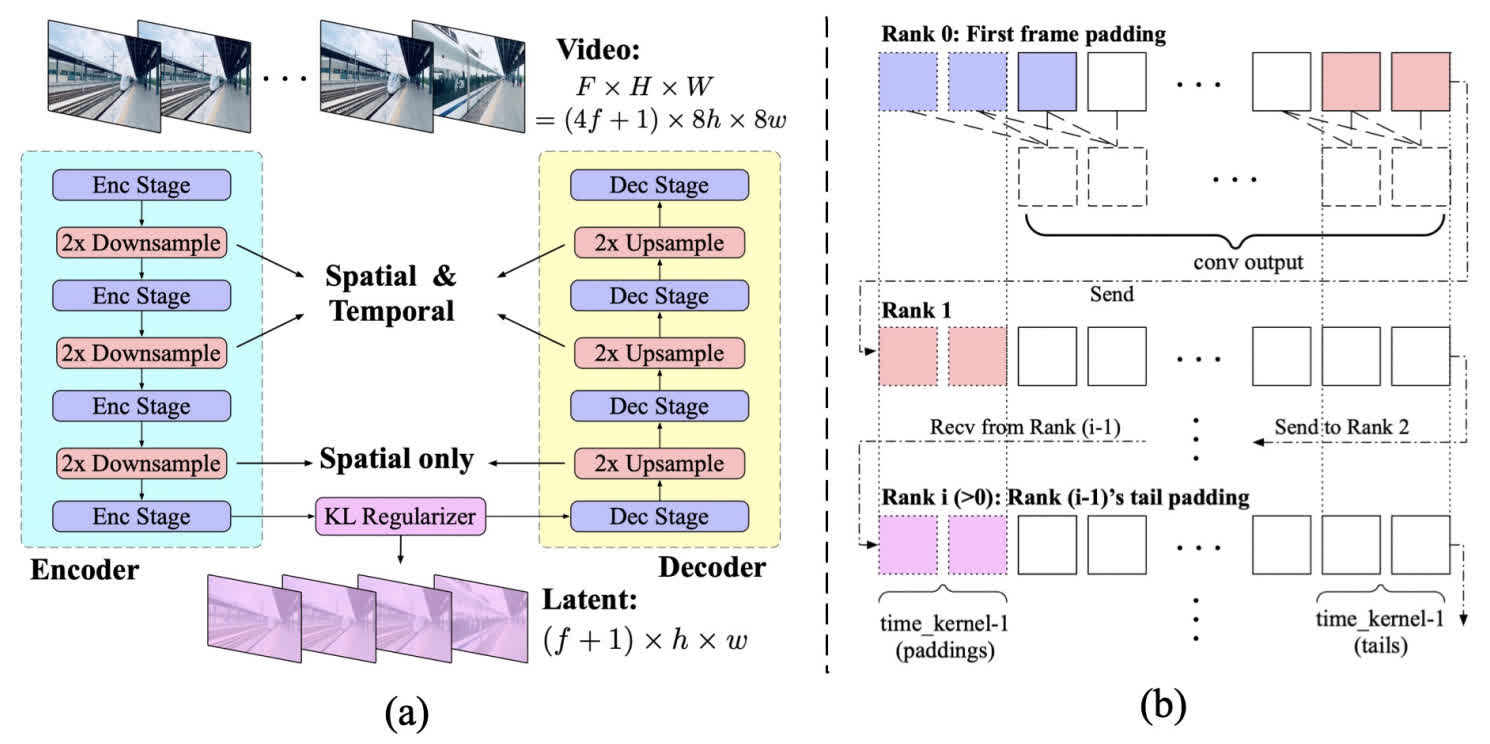
3D Causal VAE
由于视频相比图像多了时序信息,所以需要对多出来的时间维度进行处理。先前的视频生成模型都采用 2D VAE,这样会导致生成的视频在时间上连续性比较差,并且出现闪烁的情况。
和通常的 VAE 相同,3D Causal VAE 包括一个编码器、一个解码器以及一个 KL 约束。在编码的前两个阶段,分别在时间和空间维度上进行 2 倍下采样,在最后一个阶段只在空间维度上进行下采样。因此最后的下采样倍数是 \(4\times8\times8\),时间维度倍数为 4,空间为 8 倍。
为了防止未来的时序信息泄漏到当前或更早的时间中,这里采取了一种特殊的 padding 方式,也就是只在前方进行 padding,这样卷积时就不会把后续 token 的信息泄露到当前 token。并且这种卷积还可以在不同 GPU 之间进行并行,只需要在不同的 GPU 之间拷贝少量的数据(图 b 中的鲑鱼粉色 token)即可。
Expert Transformer
CogVideoX 采取和 SD3 类似的 MMDiT 架构,下面来依次介绍这种架构中的各组成部分。
Patchify
CogVideoX 的分块策略和 DiT 的相同,同时为了使模型能够同时在视频和图像数据上进行训练(这部分会在训练策略部分介绍),并不在时间维度上进行分块。也就是说对于一个大小为 \(T\times H\times W\times C\) 的输入,会分成长度为 \(T\times H/p\times W/p\) 的序列。
3D 旋转位置编码
视频经过 patchify 后,每个位置可以用一个三维坐标 \((x,y,t)\) 来表示,CogVideoX 的做法是对每一个坐标分别进行旋转位置编码,再沿通道直接拼接到一起。其中,表示空间位置的坐标分别占 \(3/8\),表示时间的坐标占 \(2/8\)。
Expert Transformer Block
这部分花了两段来讲 Transformer Block 的架构,然而感觉和 SD3 并没有什么区别。就是两个模态分别做 projection 和 AdaLN,然后再用注意力做特征交互,最后和 DiT 一样用一个 scale 参数进行 gating。不知道这里是不是我有什么没理解到位,目前感觉这个架构和 SD3 的没有什么区别。
3D Full Attention
先前的方法为了降低计算量而在时序和空间上分别计算 attention,这样会导致当视频的变化比较快速的时候出现前后不一致的情况。因此这里使用了 Full Attention,应该是对整体的所有 token 计算 attention,而不是时间和空间分开。
CogVideoX 的训练
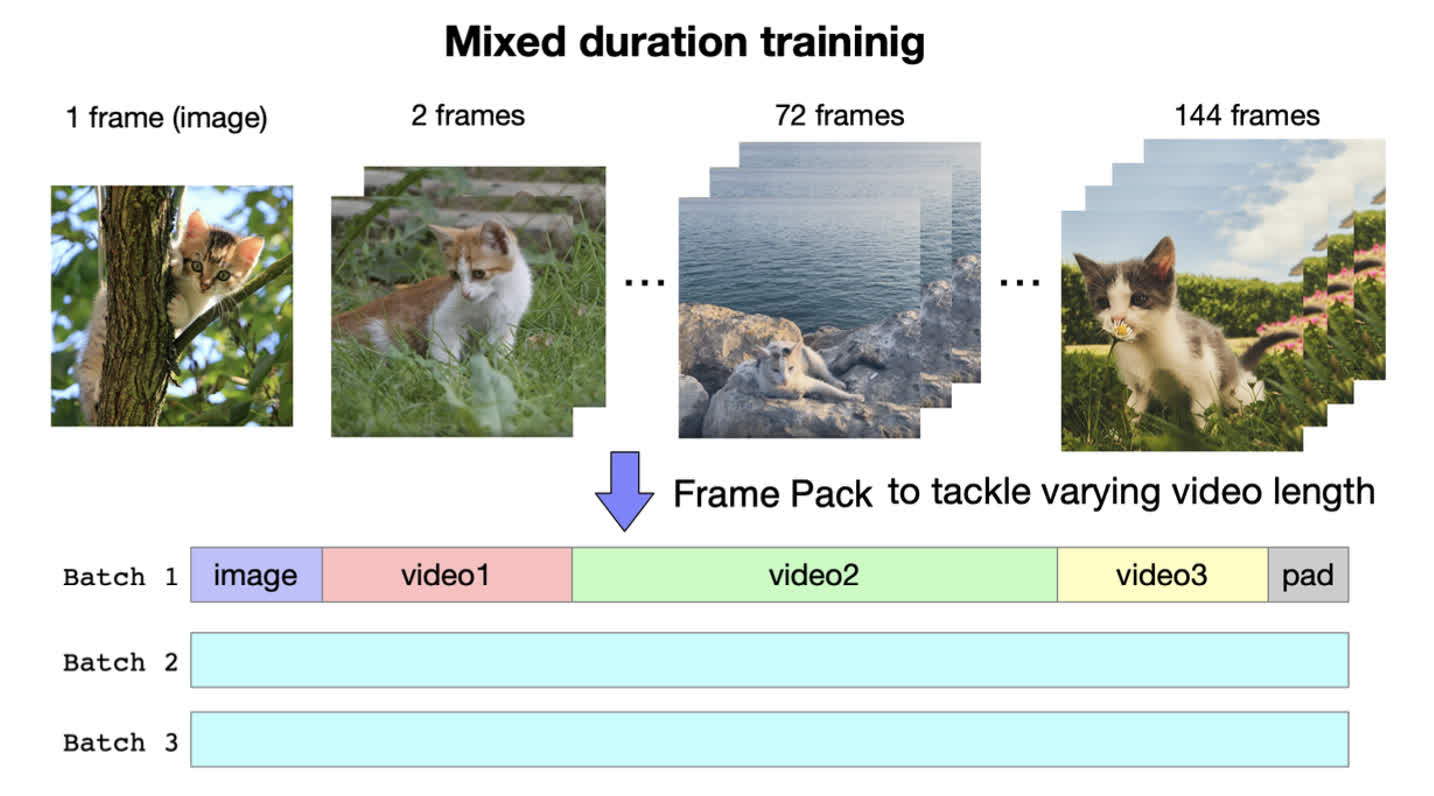
Frame Pack
CogVideoX 采用了图像与视频混合训练的方式,在进行训练时,将图像视为长度只有一帧的视频。并且 CogVideoX 并没有采用和其他方法相同的定长视频训练,而是采用了一种打包训练的方法,通过把不同长度的视频都打包在一个 batch 中,来确保不同 batch 维度相同。
Resolution Progressive Training
CogVideoX 也采取了多分辨率训练的策略,一方面是为了充分利用从互联网得到的带有多种分辨率的数据,另一方面是为了使模型能够渐进式地学习从粗糙到精细的多种信息。

由于模型最开始的训练阶段是在低分辨率数据上训练的,所以在高分辨数据上训练时,需要将位置编码拓展到高分辨率上。在拓展时,有两种策略,其一是将位置编码进行外推,这样可以比较好地维持不同像素之间的相对位置关系;其二是将位置编码进行插值,这样可以更好地维持像素在整个图像上的全局位置。经过测试可以发现前者可以更好地生成细节,而后者生成的结果比较模糊。最终 CogVideoX 使用的是前者。
在最后一个训练阶段,使用了高质量数据进行微调。主要包括移除了字幕以及水印的数据,这部分数据占全部数据的比例大概为 20%。
Explicit Uniform Sampling
在扩散模型进行训练时,会对时间步进行均匀采样。然而不同时间步对应的损失的尺度可能不一致,因此虽然对时间步的采样是均匀的,但最后得到的损失却不够均匀。为此,CogVideoX 使用了一种显式均匀采样的方法,具体来说,在并行训练时会为每个 rank 分配一个时间步的区间,然后每个 rank 都只在这个区间里进行均匀采样,这样能够得到比较均匀的 loss,有助于模型更好地收敛。
Data
作者通过筛选与打标构造了一个大小约为 35 M 的视频-文本数据集,平均每个视频片段的长度为 6 秒。
在构造时首先需要对视频进行筛选,首先定义了一系列标签,表示视频存在的问题。例如人工编辑痕迹、运动连续性差、视频质量低、讲座(一个人一直在说话的视频)、以文本为主的视频、屏摄等。作者先随机采样了 20000 段视频,然后对这些视频进行了上述标签的标注。基于这些标注,训练了一个 video-llama 模型用来筛选低质量的视频数据。除此之外作者也使用了光流与图像美学分数来保证视频的质量。
在数据标注方面,作者构造了一个为视频提供详细标注的 pipeline。作者首先用 Panda70M 模型来为视频生成简短的标注,然后用 CogVLM 和 CogView3 来为每一帧生成标注,最后用 GPT-4 来总结上述内容,生成最终的视频标注。为了加速最后一个步骤,作者还对 GPT-4 的结果进行了蒸馏,微调了一个 llama 2 来代替 GPT-4。
总结
感觉 CogVideoX 的工作量的确是非常大的,其实模型架构还是比较常规的,类似 3D 版的 SD3。不过这个工作之所以能获得比较大的效果,我个人感觉和精细的数据工程关系是很大的。随着现在大模型的发展,数据的质量也已经成为模型训练能否成功的关键因素,因此上述的数据处理流程还是非常值得学习的。