笔记|扩散模型(一五)CogVideo 论文解读|文生视频大模型
论文链接:CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
官方实现:THUDM/CogVideo(由于目前的仓库里,CogVideo 相关的代码已经被替换为 CogVideoX 的代码,所以如果希望浏览 CogVideo 的代码,包含该方法代码最后一个 commit 为
5f914b7,也就是 这个链接)
和本系列中的 DALL-E 一样,虽然 CogVideo 也并非基于扩散模型的方法,但由于其后续工作 CogVideoX 是基于扩散模型的,所以这篇文章也放到扩散模型系列里。
CogVideo 是基于大规模预训练 Transformer 进行视频生成的工作,也是近期推出的 CogVideoX 的前身。相比于文生图任务,文生视频的主要难点在于两个方面:首先是数据更加稀缺,视频-文本配对数据比较少;其次是视频多了时序信息。
本模型基于文生图模型 CogView2 进行训练,在训练时使用了 5.4 M 视频-文本对数据。在训练时,文本条件是通过 in context learning,也就是将文本 token 直接拼接在图像 token 序列前方的方式实现的。除此之外还引入了多帧率层次化训练的训练策略,通过调整帧率来动态地调整视频的长度。在生成时,首先生成关键帧,然后用一个插值模型生成中间帧。
CogVideo
CogVideo 的整体架构如下图所示,可以看到从上到下分别包括几个部分。最上方是 text condition 以及输入视频帧;中间是一个只有 5 帧作为输入的 transformer,并且输入的序列包括一个帧率 token、一些文本 token 和一些图像 token;最下方是一个用来做递归插值的 transformer 模型。
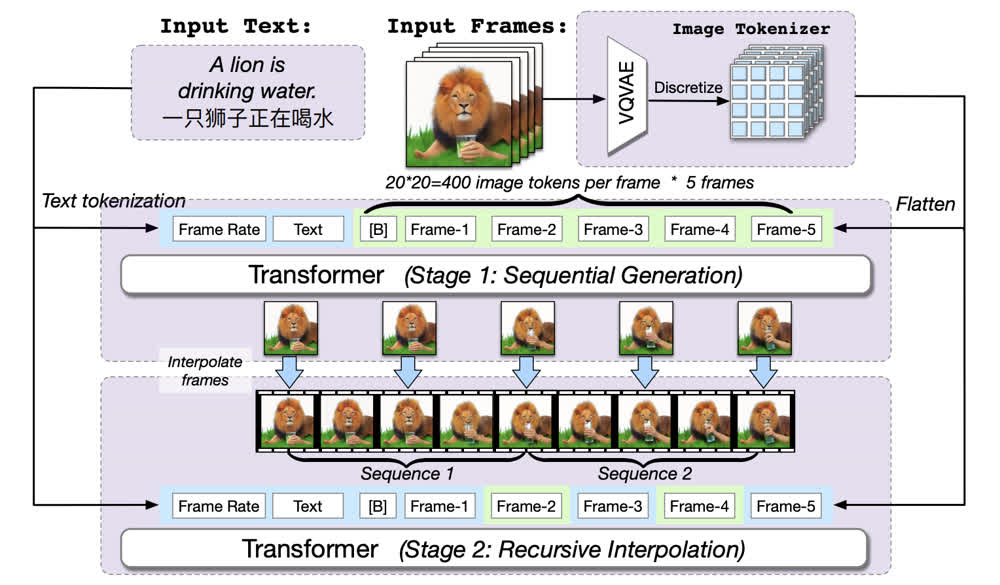
多帧率层次化训练
CogVideo 也采用了比较常见的方式,用 VQVAE 将视频序列转换为离散的 token 序列,再使用 transformer 对 token 序列进行学习。在训练时,token 序列的长度是固定的,也就是总共包含对应于 5 帧的 token 序列。不过和通常的方法不同的是,这里虽然序列的长度是固定的,但是实际上对应的视频的长度是可变的。
具体来说,CogVideo 在序列开始的时候加入了一个表示帧率的 token
Frame Rate。虽然论文原文直接把这个称为
framerate,不过这个和实际上视频的帧率感觉还是有一点区别的。这个表示的是在这个序列的
5
帧中,每两帧之间相隔的视频中帧的数量。这样,对于比较长的视频,可以设置两帧之间相隔较多帧,反之亦然。有了这个设定,无论训练视频多长都可以用固定的序列长度表示,可以实现对变长视频的处理。
这样做主要有两点好处:
- 首先是可以处理变长视频,防止因对视频进行截断导致与文字之间的不对齐现象;
- 其次是在一般的视频中,相邻帧一般比较类似,如果直接对原始数据进行学习,容易让模型学到直接 copy 上一帧的 shortcut,导致模型退化。
不过这样训练之后的模型生成的两帧之间也会比较跳跃,因此需要用一个额外的插帧模型对生成的关键帧进行插帧。
在生成阶段,首先依然是需要生成最开始的五个关键帧,在生成关键帧后,CogVideo 采用了一种递归的插帧方式。具体来说就是在现有帧的基础上,将帧率减半,然后在每两帧之间再用自回归的方式生成一帧,这样每次生成之后序列的长度就会变成原来的 2 倍。(但因为整体的 token 序列长度不变,所以每次需要拆成两半插帧两次)
除此之外,CogVideo 还使用了 CogLM 的双向注意力机制,不同于 GPT 等只有单向注意力的模型,引入双向注意力可以使生成过程关注前后文的信息。
双通道注意力
相比于图像生成模型,视频生成模型需要关注时序信息。为此,CogVideo 直接在文生图模型 CogView2 上进行改进,因为后者已经能比较好地处理文本-图像的信息,所以可以作为视频生成模型的预训练。
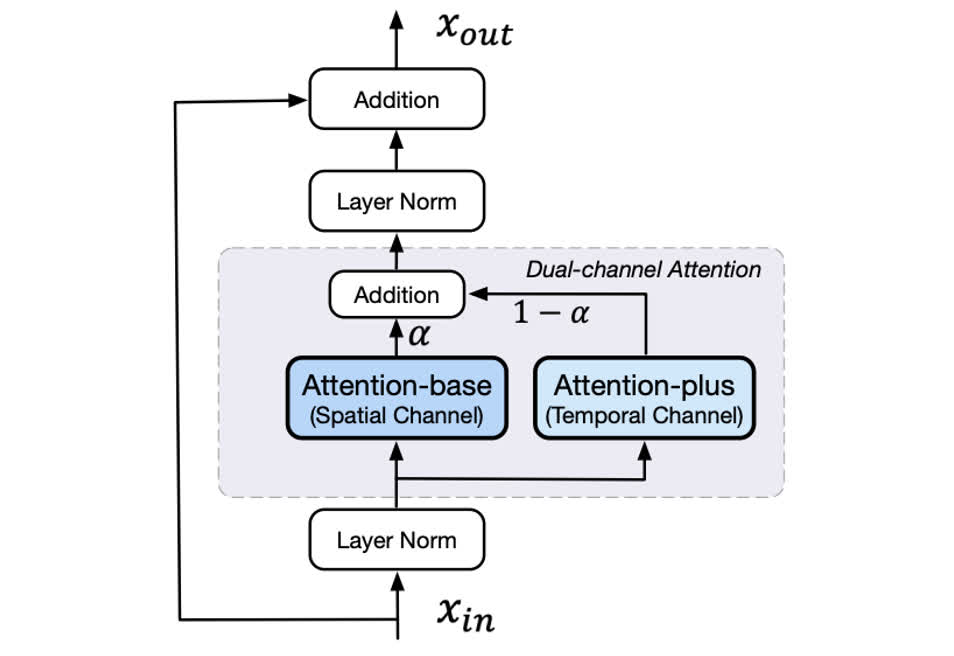
为了使模型能够比较好地处理时序信息,CogVideo 在原有的 attention 的基础上又加入了一个 3D attention,如下图所示。图中的 Attention-base 就是原来的 CogView2 自带的 attention,其是以图像作为单位进行处理,可以理解为每次计算 attention 都是在图像内部做,主要关注的是图像级别的生成。而 Attention-plus 则是 3D 注意力,在进行 attention 计算的时候有多帧的内容都参与计算,这样可以关注时序信息。
对于 Attention-plus 的选择,原文使用了两种选择,即 3D local attention 和 3D Swin attention。两个通道的 attention 加权求和后作为双通道注意力的整体输出。
生成阶段的滑窗注意力
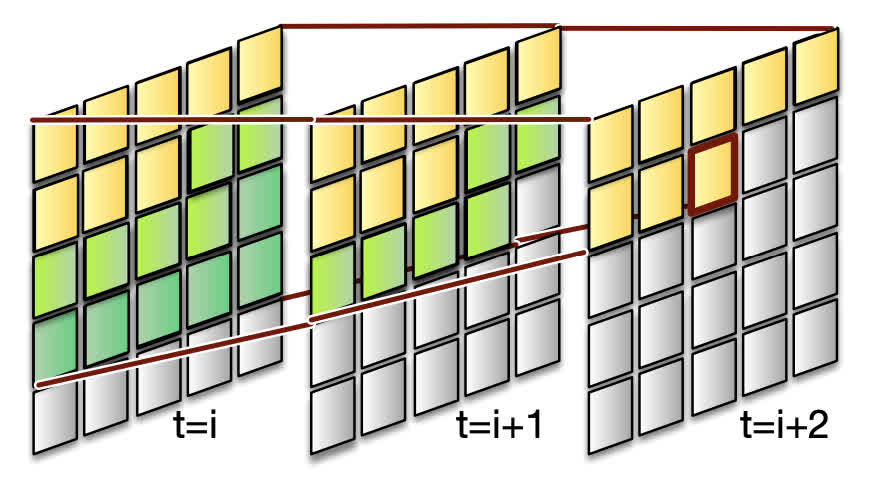
正常的 3D Swin attention 是不支持自回归生成过程的,因此 CogVideo 为了让这个注意力机制能够支持自回归生成,加入了一个自回归 mask 机制。并且这样可以让不同的帧能够在一定程度上并行生成。
具体的做法如下图所示,这里展示的是窗口大小为 2 的情况。图中的
t=i、t=i+1、t=i+2
表示相邻的三帧,后边的帧可以看到的前帧的范围就只有不是灰色的部分,因为窗口有一定的大小,所以可以看到的前帧中
token 的范围比当前已经生成的更多。这样就相当于第 i
帧的深绿色部分生成完的时候,第 i+1
帧就可以生成浅绿色的部分,第 i+2 帧就可以生成红框圈住的
token,从而实现并行。(虽然感觉这种并行在实现上也还是有点复杂)
总结
因为 CogVideo
的代码比较复杂,感觉阅读起来略困难,而且很多部分都被集成到了智谱开源的
SwissArmyTransformer
库中,所以这篇论文没有对应的代码分析。感觉这篇文章的方法还是很巧妙的,在时序维度上一步步上采样颇有
VAR 的感觉。这个方法后续也推出了 CogVideoX,这是一个基于 Diffusion Model
的方法,后续我也会做一期解读,敬请期待。