笔记|扩散模型(一四)Textual Inversion 理论与实现
论文链接:An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
官方实现:rinongal/textual_inversion
非官方实现:huggingface/diffusers
Textual Inversion 也是对 diffusion model 进行微调的主要范式之一,从标题中 An Image is Worth One Word 可以猜测,这个方法也是类似 Dreambooth 用某个特别的 text token 来表示所要生成的物体。不过和 Dreambooth 不同的是,Textual Inversion 并不是在 prompt 中插入某个修饰词来表示主体或者风格,而是直接将主体学习为一个 token。这个方法比较特别的是它并不改变原始模型的权重,而只学习了一个额外的 embedding。
Textual Inversion
现有的工作已经证明了 diffusion model 的 text embedding 空间对图像的语义信息有一定的理解能力,然而这些 embedding 都是用对比学习(CLIP)或者文本补全(BERT)的方法来训练的,这两者都对图像的理解能力没有比较高的要求。这样做的结果就是模型无法精确地理解想要生成的目标,例如有的时候会出现图像的语义错乱的问题。因此,作者把对 text embedding 的学习当成一个图像领域的任务。
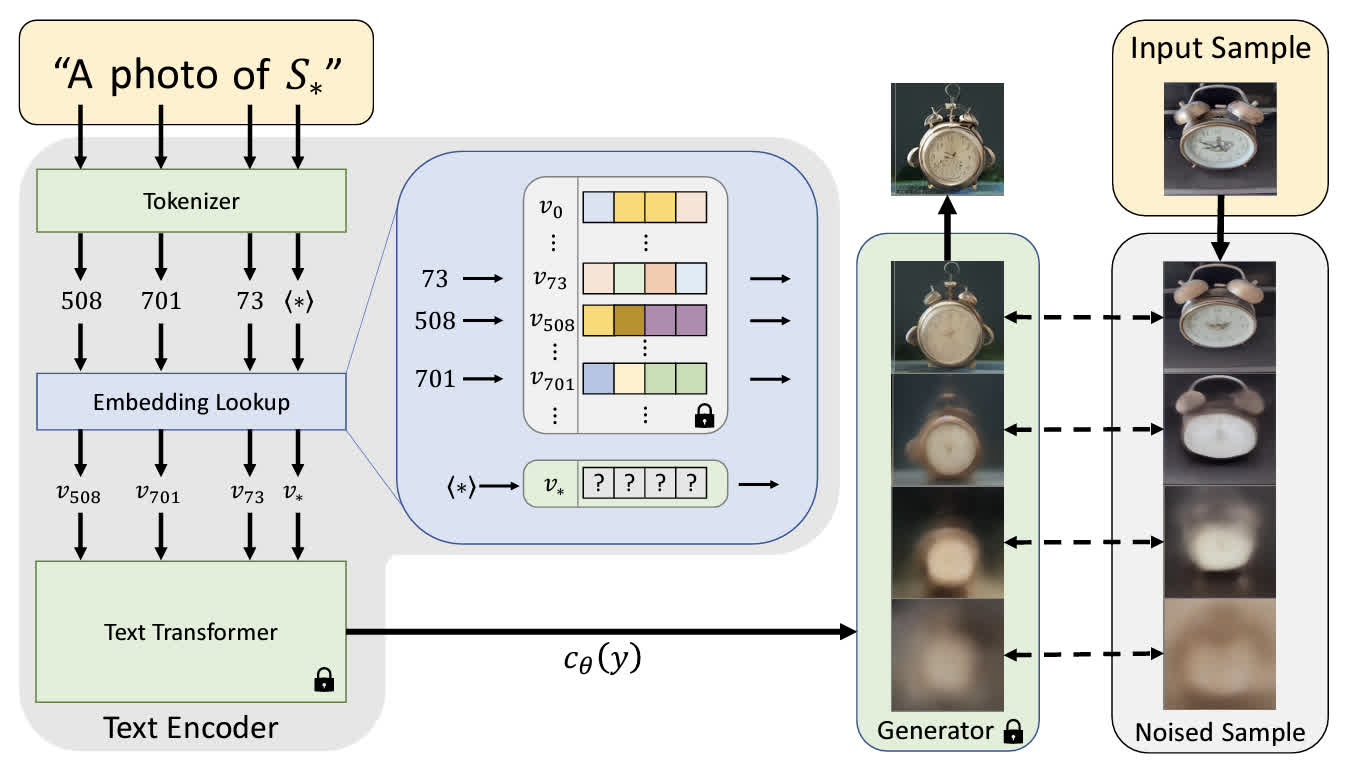
现有的 text embedding 通常是先将文本转换为 token,这些 token 再用文本模型转换为对应的 embedding。在 Textual Inversion 中,将 inversion 的目标定为 embedding 空间。作者用一个占位符 \(S_*\) 表示要学习的主体,然后把这个占位符相关的 embedding 全都替换为某个可学习的 embedding,用这种方式把要生成的主体嵌入到词表中。从上图中的 embedding lookup 可以发现,其他的 token 都是通过一个文本模型实现的 embedding,而这个占位符是一个独立于文本模型的单独可学习 embedding。
由于这个新的 embedding 是需要学习的,需要用一小组图片(大概 3-5 张)对其进行训练,训练的 loss 是对 LDM 的损失进行最小化,这个的确是一个视觉任务,因此能够将这个 embedding 和某个具体的视觉概念绑定起来。在训练的时候,text prompt 是从 CLIP ImageNet templates 中采样出来的,大概都是一些 A photo of \(S_\star\) 或者 A rendition of \(S_\star\) 一类的句子。另一个比较需要注意的是,这个 embedding 并不是随机初始化的,而是用对学习的目标的比较粗糙的单个单词描述初始化,比如图里的例子就可以用 clock 初始化。
Textual Inversion 所学习的 embedding 并不仅仅能用来进行主体生成,同时也可以用来进行 style transfer 或 image editing。同时,可以组合多个学习到的 embedding,同时实现不同的生成目标。
代码实现分析
这里基于 diffusers
中的实现进行分析。首先是数据处理,在这里的数据集主要有两个特殊的地方(无关的部分已经去掉,只留下了关键信息):
1 | class TextualInversionDataset(Dataset): |
可以看到有两个需要手动指定的参数,其一是学习的目标(是一个物体还是一种风格),其次是占位符的 token,这里使用的是一个星号。根据学习的目标不同,数据集使用的 template 也有所区别,这里节选了一些,可以发现 style 的都显式地表明了是某某风格。
1 | imagenet_templates_small = [ |
在训练时,参数中给出了一个
initializer_token,这个被用来初始化那个可学习
embedding:
1 | # Convert the initializer_token, placeholder_token to ids |
可以看到用来初始化的 token 必须是单个单词,这个 token 的 id 被记录下来,用于后续的初始化:
1 | # Initialise the newly added placeholder token with the embeddings of the initializer token |
对于 placeholder token,处理后加入了 tokenizer,可以看到占位符必须是 tokenizer 中本来没有的:
1 | # Add the placeholder token in tokenizer |
在优化器中,看起来这里把所有 input embedding 的参数都传进去了,暂时不太清楚是不是只有新加入的 token 是参数,其他的不是:
1 | optimizer = torch.optim.AdamW( |
总结
相比于 Dreambooth 来说,textual inversion 更加简单粗暴,直接加入了一个新的 embedding。可以想象增加的额外参数量是非常小的,最后保存下来的 checkpoint 就只有几 kb。而且 textual inversion 的训练同样也只需要几张图片,这样只要有了一个基础模型,就可以快速地获得很多种新的风格的生成模型,还是很神奇的。