笔记|扩散模型(一三)DiT|Diffusion with Transformer
论文链接:Scalable Diffusion Models with Transformers
官方实现:facebookresearch/DiT
Transformer 在许多领域都有很不错的表现,尤其是近期大语言模型的成功证明了 scaling law 在 NLP 领域的效果。Diffusion Transformer(DiT)把 transformer 架构引入了扩散模型中,并且试图用同样的 scaling 方法提升扩散模型的效果。DiT 提出后就受到了很多后续工作的 follow,例如比较有名的视频生成方法 sora 就采取了 DiT 作为扩散模型的架构。
Diffusion Transformer
在正式开始介绍 DiT 之前,需要先了解一下 DiT 使用的扩散模型架构。DiT 使用的是 latent diffusion,VAE 采用和 Stable Diffusion 相同的 KL-f8,并且使用了 Improved DDPM(详细介绍见这个链接),同时预测噪声的均值和方差。
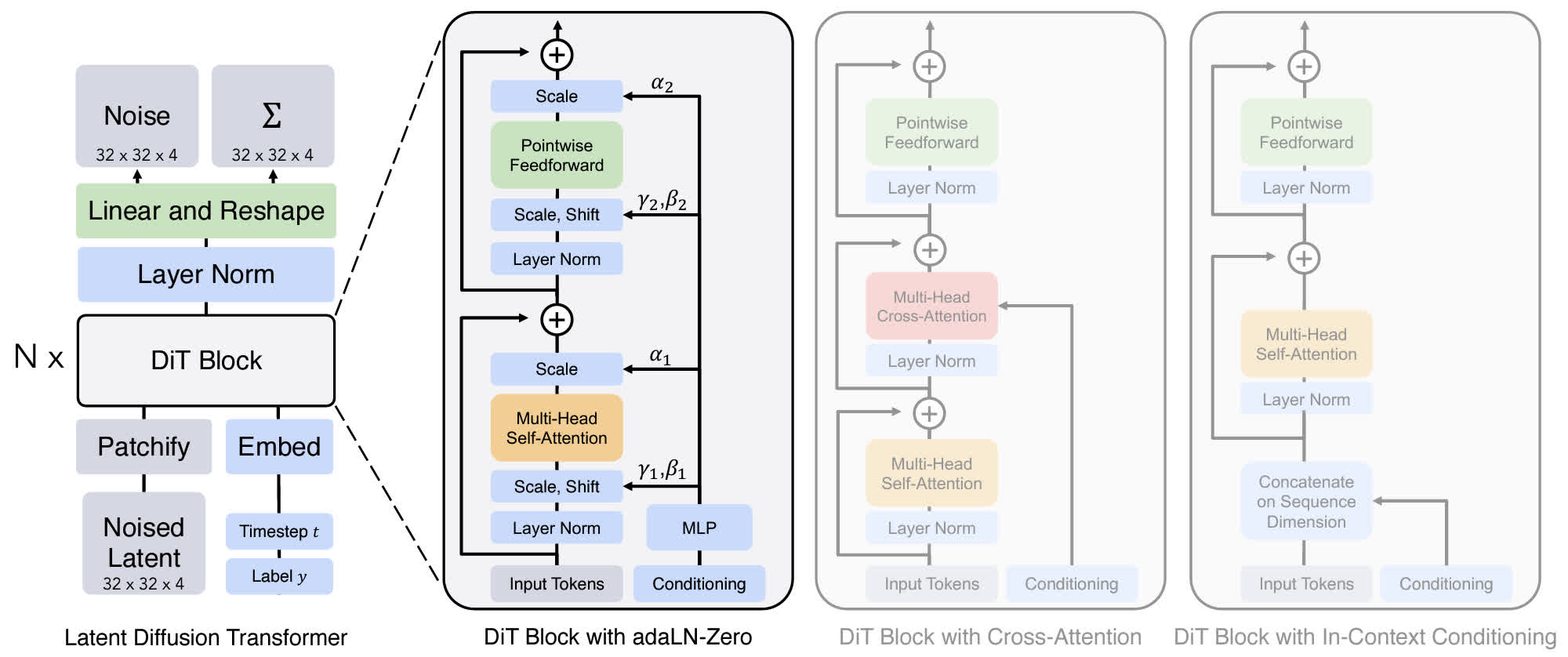
Patchify
由于 DiT 使用了 latent diffusion,对于 \(256\times256\times3\) 的输入图像,首先使用 VAE 转换为 \(32\times32\times4\) 的 latent,在 latent 输入到 DiT 之前,首先需要将其转换为 token,也就是 patchify。DiT 的 patchify 方式和 ViT 基本上相同,也就是将图像变成 \((I/p)^2\) 个 patch,其中 \(I\) 是 latent 的 spatial size,\(p\) 是每个 patch 的大小,这里 \(p\) 的取值使用了 2、4、8 几个取值。在转换为 patch 后,还需要给每个 patch 加上位置编码,这里的位置编码使用的是二维的不可学习 sin-cos 位置编码。
DiT Block Design
DiT 的 block 大部分结构都可以直接沿用 ViT 的结构,不过和 ViT 不同的是,DiT 除了需要接收 token 的输入,还需要将 time embedding 和生成条件也进行嵌入。为此,作者设计了四种方式:
- In context conditioning:用类似 ViT 的方法,把 time embedding 和 condition 作为额外的 token 输入到 DiT 中,并且在最后把这两部分 token 去掉。这个做法和 U-ViT 是一样的,不过会增加一部分额外的计算开销;
- Cross-attention block:使用和原版 Transformer 类似的设计,在 self-attention 层后方再加一个 cross-attention 层,把 time embedding 和 condition 作为一个长度为 2 的序列输入,latent 作为 query,条件作为 key 和 value,这种方式引入的额外开销比较大;
- Adaptive layer norm:将 transformer block 中的 LayerNorm 换成 AdaLayerNorm,用 time embedding 和 condition embedding 回归 shift 和 scale 参数,用来对 latent 进行 affine;
- AdaLN-Zero block:根据一些现有的工作的经验,把残差连接前的最后一个卷积初始化为 0 对训练比较有利,因此这里将 AdaLN 中的线性层(对应上图中的 \(\gamma\) 和 \(\beta\))进行 0 初始化,并且在最后加入另一个可学习的 scale(对应上图的 \(\alpha\)),也初始化为 0。
经过实验发现 AdaLN-Zero 的设计是最好的,因此 DiT 最终采用的是这种设计方案。
其他
和 ViT 相同,通过修改 transformer block 的数量、隐变量的维度,以及 attention head 的数量,可以得到不同大小的 DiT(DiT-S、DiT-B、DiT-L 和 DiT-XL),这些模型的 flop 从 0.3 GFLOPs 到 118.6 GFLOPs 不等。
对于 decoder,DiT 使用一个 LayerNorm(或 AdaLN)以及一个线性层对输出进行编码。最后得到的输出的大小为 \(p\times p\times 2C\),通道数为 \(2C\) 是因为包括了均值和方差。
讨论
作者进行了一系列实验来研究不同 DiT 设计之间的区别,主要包括以下几个方面:
- DiT block 的设计:经过实验可以发现 AdaLN 的效果比其他的条件嵌入方式更好,并且初始化方式也很重要,AdaLN 将每个 DiT block 初始化为恒等映射,能取得更好的效果;不过对于比较复杂的条件,比如 text,可能用 cross-attention 更好;
- 缩放模型大小和 patch 大小:实验发现增大模型大小并减小 patch 大小可以提高性能;
- 提高 GFLOPs 是改善模型性能的关键;
- 更大的 DiT 模型的计算效率更高;
DiT 的代码实现
主要需要关注的是模型的 DiT block 和 decoder,根据官方实现:
1 | def modulate(x, shift, scale): |
可以看到所有的 affine 参数都是由同一个 MLP 学习的,推理时被 6 等分,然后对 latent 进行 affine。
Decoder 则是由 AdaLN + Linear 组成:
1 | class FinalLayer(nn.Module): |
这些 adaLN_modulation 层在创建时被零初始化:
1 | # Zero-out adaLN modulation layers in DiT blocks: |
总结
个人感觉 DiT 相比于 U-ViT 是更成功的,因为我们使用 transformer 架构比较注重的就是缩放能力,而 DiT 的实验表明,其性能能够随着模型的缩放(模型规模/模型计算量)而受益。