笔记|扩散模型(一二)U-ViT|Diffusion with Transformer
论文链接:All are Worth Words: A ViT Backbone for Diffusion Models
官方实现:baofff/U-ViT
扩散模型自从被提出后,主干网络一直都是各种基于卷积的 UNet 的变体。而在其他领域,Transformer 架构则更加流行,尤其是由于 Transformer 多模态性能和缩放能力都很强,因此把 Transformer 架构用于扩散模型是很值得尝试的。这篇 U-ViT 的工作就是一个不错的尝试。
U-ViT 的设计
在开始具体的介绍之前,可以先看一下 U-ViT 整体的架构。可以看出其有几个主要的特点:
- 所有的元素,包括 latent、timestep、condition 等都以 token 的形式进行了 embedding;
- 类似于 UNet,在不同的 Transformer Block 层之间添加了长跳跃连接。
虽然理论上来说这两个点都比较简单,但作者进行了一系列实验来选择比较好的设计。
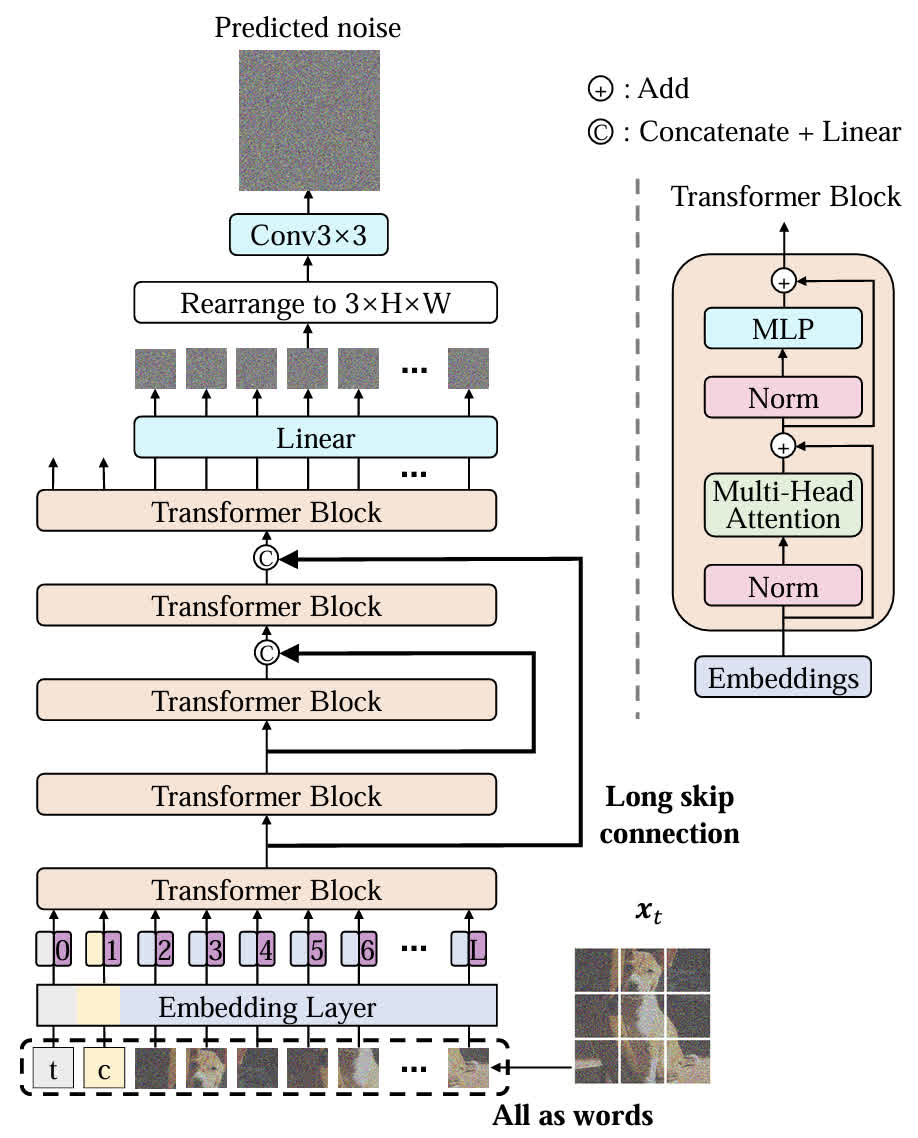
长跳跃连接的实现
将主分支和长跳跃连接分支的特征分别记为 \(h_m\) 和 \(h_s\)。作者选取了几种不同的实现方式进行实验:
- 将两个特征拼接起来然后用一个线性层做 projection:\(\mathrm{Linear}(\mathrm{Concat}(h_m,h_s))\);
- 两者直接相加:\(h_m+h_s\);
- 对长跳跃连接分支做 projection 再相加:\(h_m+\mathrm{Linear}(h_s)\);
- 先相加再做 projection:\(\mathrm{Linear}(h_m+h_s)\);
- 直接去掉长跳跃连接(这个相当于对照组)。
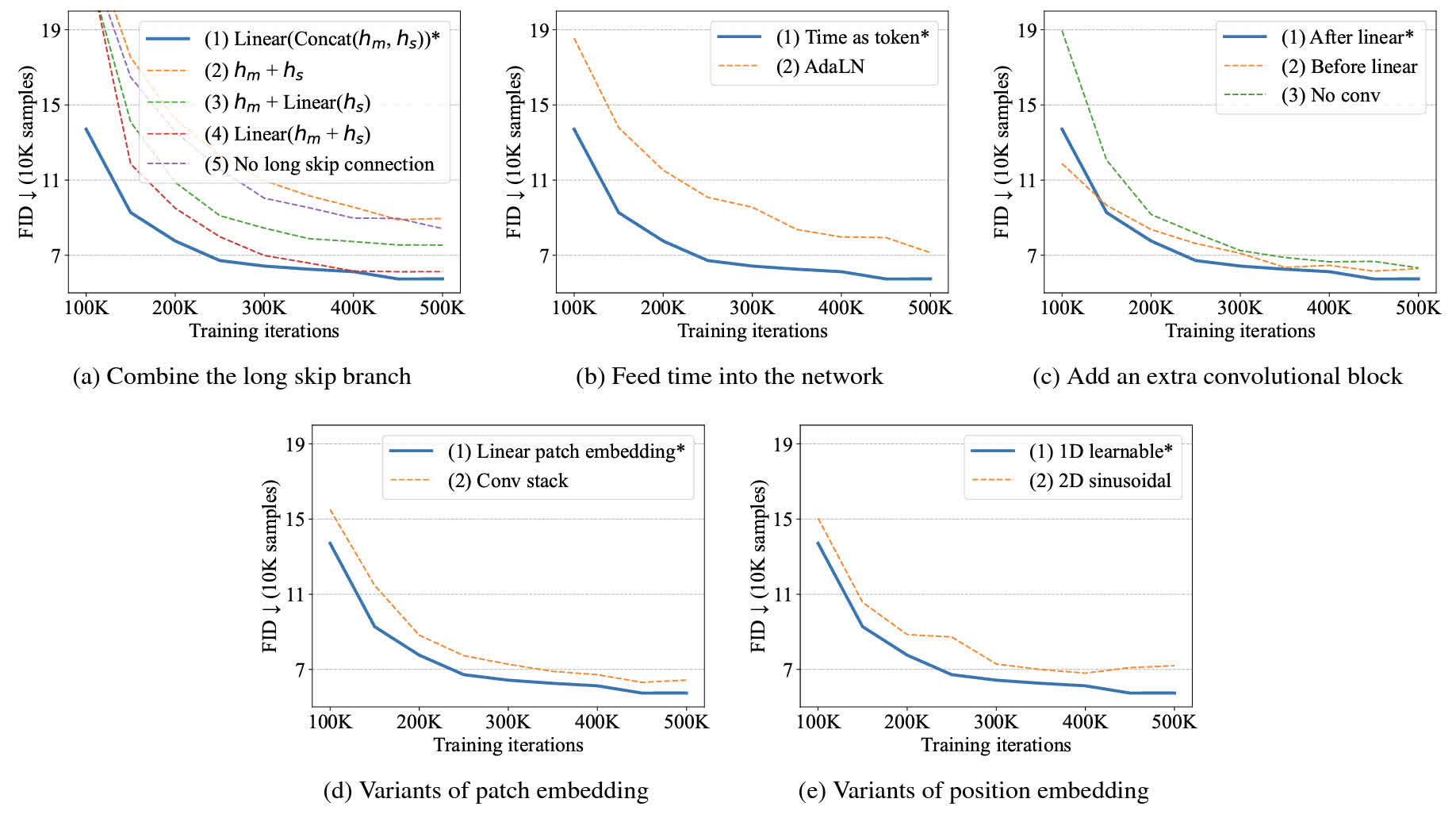
因为 Transformer block 中本来就有短跳跃连接,所以 \(h_m\) 本身就含有一部分 \(h_s\) 的信息,直接将两者相加意义不大。最后经过实验(可以看下方图里的 (a))发现第一种设计的效果最好。
Time Embedding 的实现
时间步的嵌入可以用 ViT 的风格也可以用 UNet 的风格,具体来说是:
- 把 time embedding 当成一个 token 输入;
- 在 transformer block 的 layer normalization 的位置嵌入,也就是使用 AdaLN:\(\mathrm{AdaLN}(h,y)=y_s\mathrm{LayerNorm}(h)+y_b\),其中 \(y_s\) 和 \(y_b\) 是两个 time embedding 的 projection。这个相当于用 time embedding 对 layer normalization 的结果进行 affine。
最后发现第一种方法更佳有效,如下图中的 (b) 所示。
在 Transformer 后使用卷积的方式
作者也尝试了三种方法:
- 直接在 linear projection 后使用 3x3 卷积,把 token 转换为 image patch;
- 在 projection 前先把 token embedding 转换为二维,卷积后再 projection;
- 直接不加入额外的卷积层。
最后发现第一种方式效果最好,如下图中的 (c) 所示。
Patch Embedding 的实现
有两种方法:
- 直接用 linear projection 进行 embedding;
- 用一系列 3x3 卷积+1x1 卷积进行 embedding。
最后发现第一种方法的效果更好,如下图中的 (d)。
Position Embedding 的实现
- 和 ViT 的 setting 相同,使用一维的可学习向量;
- 使用 NLP 领域常用的 sinusoidal position embedding 的二维形式。
经过实验发现前者效果更好,如下图的 (e) 所示。
总而言之作者通过一系列实验确定了一个比较好的 U-ViT 的设计。
讨论:U-ViT 的缩放能力
作者尝试了更深/更宽的模型架构,以及更大的 patch,最后发现性能随着深度和宽度的增加,并不是单调上升的,最佳的效果都在中等宽度/中等深度的网络中取得。
除此之外,作者发现最小的 patch 能够取得最佳的结果,这可能是因为预测噪声是比较 low-level 的任务,所以更小的 patch 更合适。由于对于高分辨率图像使用小 patch 比较消耗资源,所以也需要先将图像转换到低维度的隐空间中再进行建模。
总结
除了 U-ViT 之外,同期的 DiT 也把 transformer 架构引入到了扩散模型中,虽然感觉作者的实验思路非常简单粗暴,但最后的效果还是不错的。从后续的工作也可以看出,这类 transformer 架构的方法在某些任务上(例如视频生成)有取代 UNet 的趋势。