笔记|扩散模型(一一)Stable Diffusion XL 理论与实现
论文链接:SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
官方实现:Stability-AI/generative-models
非官方实现:huggingface/diffusers
Stable Diffusion XL (SDXL) 是 Stablility AI 对 Stable Diffusion 进行改进的工作,主要通过一些工程化的手段提高了 SD 模型的生成能力。相比于 Stable Diffusion,SDXL 对模型架构、条件注入、训练策略等都进行了优化,并且还引入了一个额外的 refiner,用于对生成图像进行超分,得到高分辨率图像。
Stable Diffusion XL
模型架构改进
SDXL 对模型的 VAE、UNet 和 text encoder 都进行了改进,下面依次介绍一下。
VAE
相比于 Stable Diffusion,SDXL 对 VAE 模型进行了重新训练,训练时使用了更大的 batchsize(256,Stable Diffusion 使用的则是 9),并且使用了指数移动平均,得到了性能更强的 VAE。
需要注意的是,SD 2.x 的 VAE 相对 SD 1.x 只对 decoder 进行了微调,而 encoder 不变。因此两者的 latent space 是相同的,VAE 可以互相交换使用。但 SDXL 对 encoder 也进行了微调,因此 latent space 发生了变化,SDXL 不能用 SD 的 VAE,SD 也不能用 SDXL 的 VAE。另外,由于 SDXL 的 VAE 在 fp16 下会发生溢出,所以其必须在 fp32 类型下进行推理。
UNet
SDXL 使用了更大的 UNet 模块,具体来说做了以下几个变化:
- 为了提高效率,使用了更少的 3 个 stage,而不是 SD 使用的 4 个 stage;
- 将 transformer block 移动到更深的 stage,第一个 stage 没有 transformer block;
- 使用更多的 transformer block。
详情可以看下边的表格,可以看到第二个 stage 和第三个 stage 分别使用了 2 个和 10 个 transformer block,最后 UNet 的整体参数量变成了大约 3 倍。
| 模型 | SDXL | SD1.4/1.5 | SD 2.0/2.1 |
|---|---|---|---|
| UNet 参数量 | 2.6 B | 860 M | 865 M |
| Transformer block 数量 | [0, 2, 10] | [1, 1, 1, 1] | [1, 1, 1, 1] |
| 通道倍增系数 | [1, 2, 4] | [1, 2, 4, 4] | [1, 2, 4, 4] |
Text Encoder
SDXL 还使用了更强的 text encoder,其同时使用了 OpenCLIP ViT-bigG 和 OpenAI CLIP ViT-L,使用时同时用两个 encoder 处理文本,并将倒数第二层特征拼接起来,得到一个 1280+768=2048 通道的文本特征作为最终使用的文本嵌入。
除此之外,SDXL 还使用 OpenCLIP ViT-bigG 的 pooled text embedding 映射到 time embedding 维度并与之相加,作为辅助的文本条件注入。
其与 SD 1.x 和 2.x 的比较如下表所示:
| 模型 | SDXL | SD 1.4/1.5 | SD 2.0/2.1 |
|---|---|---|---|
| 文本编码器 | OpenCLIP ViT-bigG & CLIP ViT-L | CLIP ViT-L | OpenCLIP ViT-H |
| 特征通道数 | 2048 | 768 | 1024 |
| Pooled text emb. | OpenCLIP ViT-bigG | N/A | N/A |
Refine Model
除了上述结构变化之外,SDXL 还级联了一个 refine model 用来细化模型的生成结果。这个 refine model 相当于一个 img2img 模型,在模型中的位置如下所示:
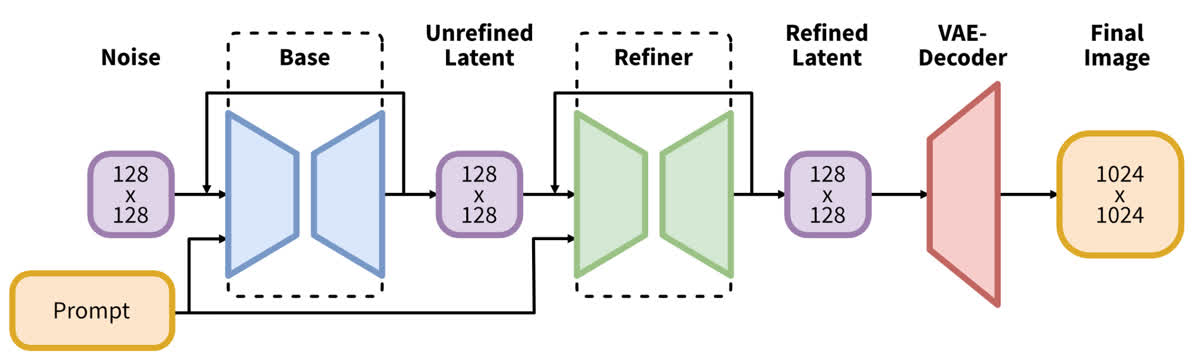
这个 refine model 的主要目的是进一步提高图像的生成质量。其是单独训练的,专注于对高质量高分辨率数据的学习,并且只在比较低的 noise level 上(即前 200 个时间步)进行训练。
在推理阶段,首先从 base model 完成正常的生成过程,然后再加一些噪音用 refine model 进一步去噪。这样可以使图像的细节得到一定的提升。
Refine model 的结构与 base model 有所不同,主要体现在以下几个方面:
- Refine model 使用了 4 个 stage,特征维度采用了 384(base model 为 320);
- Transformer block 在各个 stage 的数量为 [0, 4, 4, 0],最终参数量为 2.3 B,略小于 base model;
- 条件注入方面:text encoder 只使用了 OpenCLIP ViT-bigG;并且同样也使用了尺寸和裁剪的条件注入(这个下文会讲);除此之外还使用了 aesthetic score 作为条件。
条件注入的改进
SDXL 引入了额外的条件注入来改善训练过程中的数据处理问题,主要包括图像尺寸和图像裁剪问题。
图像尺寸条件
Stable Diffusion 的训练通常分为多个阶段,先在 256 分辨率的数据上进行训练,再在 512 分辨率的数据上进行训练,每次训练时需要过滤掉尺寸小于训练尺寸的图像。根据统计,如果直接丢弃所有分辨率不足 256 的图像,会浪费大约 40% 的数据。如果不希望丢弃图像,可以使用超分辨率模型先将图像超分到所需的分辨率,但这样会导致数据质量的降低,影响训练效果。
为了解决这个问题,作者加入了一种额外的图像尺寸条件注入。作者将原图的宽高进行傅立叶编码,然后将特征拼接起来加到 time embedding 上作为额外条件。
在训练时直接使用原图的宽高作为条件,推理的时候可以自定义宽高,生成不同质量的图像,下面的图是一个例子,可以看到当以较小的尺寸为条件时,生成的图比较模糊,反之则清晰且细节更丰富:

图像裁剪条件
在 SD 训练时使用的是固定尺寸(例如 512x512),使用时需要对原图进行处理。一般的处理流程是先 resize 到短边为目标尺寸,然后沿着长边进行裁剪。这种裁剪会导致图像部分缺失的问题,例如生成的图像部分会出现部分缺失,就是因为裁剪后的数据是不完整的。
为了解决这个问题,SDXL 在训练时把裁剪位置的坐标也当作条件注入进来。具体做法是把左上角的像素坐标值也进行傅立叶编码+拼接,再加到 time embedding 上,这样模型就能得知使用的数据是在什么位置进行的裁剪。
在推理阶段,只需要将这个条件设置为 (0, 0) 即可得到正常图像。如果设置成其他的值则能得到裁剪图像,例如下边图里的效果。(感觉还是很神奇的,竟然这种条件能 work,而且没有和图像尺寸的条件混淆)

训练策略的改进
多比例微调
在训练阶段使用的都是正方形图像,但是现实图像很多都是有一定的长宽比的图像。因此在训练后的微调阶段,还使用了一种多比例微调的策略。
具体来说,这种方法预先将训练集按照图像长宽比不同分成多个 bucket,在微调时每次随机选取一个 bucket,并从中采样出一个 batch 的数据进行训练。在原论文中给出了一个表格,从表中可以看到选取的长宽比从 0.25(对应 \(512\times2048\) 分辨率) 到 4(对应 \(2048\times512\) 分辨率)不等,并且总像素数基本都维持在 \(1024^2\) 左右。
在这个微调阶段,除了使用尺寸和裁剪条件注入,还使用了 bucket size(也就是生成的目标大小) 作为一个条件,用相同的方式进行了注入。经过这样的条件注入和微调,模型就能生成多种长宽比的图像。
Noise Offset
在多比例微调的阶段,SDXL 还使用了一种 noise offset 的方法,来解决 SD 只能生成中等亮度图像、而无法生成纯黑或者纯白图像的问题。这个问题出现的原因是在训练和采样阶段之间存在一定的 bias,训练时在最后一个时间步的时候实际上是没有加噪的,所以会出现一些问题,解决方案也比较简单,就是在训练的时候给噪声添加一个比较小的 offset 即可。
SDXL 代码解析
这里依然以 diffusers 提供的训练代码为主进行分析,模型架构的改变主要体现在加载的预训练模型中(之后应该会出一期怎么看
huggingface 里的那些文件以及 config.json
的教程),这里主要分析一下各种条件注入和训练策略是怎么实现的。
各种条件注入
首先是尺寸和裁剪的条件注入,在图像进行预处理的阶段就记录下了每张图的原始尺寸以及裁剪位置:
1 | def preprocess_train(examples): |
随后原始尺寸和裁剪位置被进行编码,可以看到下边这部分包含了三部分的条件注入:
1 | def compute_time_ids(original_size, crops_coords_top_left): |
最后把 pooled prompt embedding 也加入进来:
1 | unet_added_conditions = {"time_ids": add_time_ids} |
这样四种条件注入就都准备好了,在 forward 时直接传到 UNet 的
added_cond_kwargs 参数即可参与计算。这些参数在
get_aug_embed 中被组合起来添加到 time embedding 上:
1 | # pooled text embedding |
在上边的代码里用到了两个对象 self.add_time_proj 和
self.add_embedding,定义为:
1 | self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift) |
这两个对象中,Timesteps
应该是负责傅立叶编码,TimestepEmbedding
则负责对编码后的结果进行嵌入。
Noise Offset
这个实现很简单,就在加噪前对 noise 随机偏移一下即可:
1 | if args.noise_offset: |
多尺度微调
根据我的观察,diffusers
里没有直接提供多尺度微调相关的代码,应该是默认在训练之前已经自行处理好了各个
bucket 的图像。印象中前段时间某个组织开源了一份分 bucket
的代码,不过因为当时没保存所以现在找不到了,能找到的主要是 kohya-ss/sd-scripts
的一个实现。
大体的原理是先创建一系列桶,然后对于每张图片,选择长宽比最接近的一个桶,然后进行裁剪,裁剪到和这个桶对应的分辨率相同。由于相邻两个桶之间的分辨率之差为 64,所以最多裁剪 32 像素,对训练的影响并不大。在将图片分桶之后,则可以按照每个桶的数据比例作为概率进行采样。如果某些桶中的数据量不足一个 batch,则把这个桶中的数据都放入一个公共桶中,并以标准的 \(1024\times1024\) 分辨率进行训练。
如果读者有兴趣自己阅读代码,可以先看 library.model_util
模块中的
make_bucket_resolutions,这个方法创建了一系列分辨率的
bucket,并在 library.train_util.BucketManager
中调用,用来创建 bucket。这个 BucketManager 提供了一个方法
select_bucket,用来为某个特定分辨率的图像选择
bucket。最后在 library.train_util.BaseDataset
中,会对每张图片调用 select_bucket 选择
bucket,再将对应的图片加入到选择的 bucket 中。
总结
感觉 SDXL 是一个比较工程的工作,尤其是对模型架构的修改,比较大力出奇迹。除此之外感觉对数据的理解还是很重要的,除了修改模型架构之外的其他工作都是围绕着数据展开的,这也是比较值得学习的思路。
参考资料: