笔记|LoRA 理论与实现|大模型轻量级微调
论文链接:LoRA: Low-Rank Adaptation of Large Language Models
官方实现:microsoft/LoRA
这篇文章要介绍的是一种大模型/扩散模型的微调方法,叫做低秩适应(也就是 Low-Rank Adaptation,LoRA)。经常使用 stable diffusion webui 的读者应该对这个名词非常熟悉,通过给扩散模型加载不同的 lora,可以让扩散模型生成出不同风格的图像。现在也已经有很多平台(例如 civitai、tensorart 等)可以下载现成的 lora,可以看出 LoRA 的影响力还是比较大的。
LoRA 作为一种高效的参数微调(Parameter-Efficient Fine-Tuning,PEFT)方法,最初是被用来微调 LLM 的,后来也被用来微调扩散模型。这种方法的主要思想是固定住预训练模型的参数,同时引入额外的可训练低秩分解模块,只训练额外引入的这部分参数,从而大大减小模型的微调成本。
与其他的 Peft 方法相比,LoRA 也有一些独特的优势:
- 首先是与 adapter 的方法相比,LoRA 不引入额外推理延迟。因为 Adapter 会在模型中插入额外的 layer,在推理时这些 layer 都会引入延迟,并且在分布式训练中需要更多的进程同步操作。而 LoRA 不存在这个问题,且在推理阶段可以利用重参数化将额外的权重与原有权重合并(这个后边会介绍),从而保持推理延迟不变。
- 其次是与 prefix embedding tuning 相比,LoRA 更容易优化。并且 prefix embedding tuning 需要在序列前方插入一部分用来微调的 prompt,这种做法限制了有效 prompt 的长度。
- 除此之外,不同 LoRA 模型可以共用同一个基座模型,每次微调只需要保存额外参数。而且这种方法与其他的 peft 方法正交,可以同时使用多种 peft 方法进行微调。
LoRA 介绍
论文的作者提出本方法主要是基于一个观察:模型通常都是过参数化的,在模型的优化过程中,更新的参数集中在低维度的子空间中。同时,模型在下游任务微调后,权重的内在秩(intrinsic rank,或者叫本征秩)是比较低的,因此可以认为更新的权重也是低秩的。所谓的更新的权重,可以表示成:\(W=W_0+\Delta W\),其中 \(W_0\) 就是原始的权重、\(\Delta W\) 则是权重的变化量,也就是更新的权重。
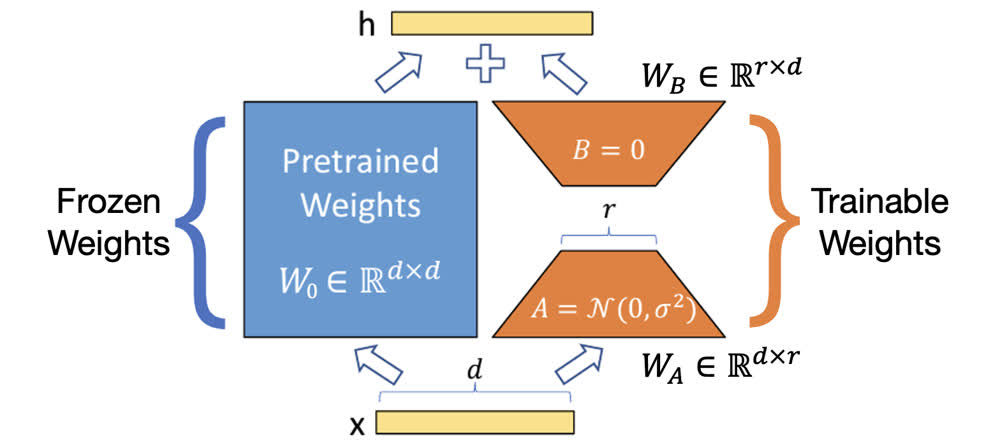
LoRA 具体的做法如上图所示,在预训练权重的旁边加入了一个新的支路,表示 \(\Delta W\)。由于上文中说的 \(\Delta W\) 具有较低的秩,因此可以对其进行低秩分解:\(\Delta W=BA\),如果原始权重 \(W\) 的维度为 \(d\times d\),低秩分解的秩为 \(r\),那么有 \(B\in\mathbb{R}^{d\times r}\)、\(A\in\mathbb{R}^{r\times d}\),并且 \(r\ll d\)。由于 \(r\) 很小,所以这部分的参数量也很小,在微调时只有这部分权重需要更新,所以训练的资源消耗并不大。
加入低秩分解模块后,模型的推理过程就变成了 \(Wx=W_0x+\Delta Wx=W_0x+BAx\)。在初始条件下,LoRA 权重分别被初始化为高斯分布与 0,如上图所示。(根据作者的意思,A 和 B 的初始化也可以反过来)这样在初始条件下,\(BAx\) 这一项为 0,相当于从原始模型开始微调。
在实际使用时,还会引入一个额外的参数用来调整 LoRA 部分的权重,也就是 \(Wx=W_0x+\frac{\alpha}{r}BAx\),一般 \(\alpha\) 会设置为一个比 \(r\) 大的值。这样做一方面是为了放大 LoRA 的效果,另一方面也是为了方便调参。
在微调结束后,推理时,由于 A 和 B 的权重矩阵相乘结果 BA 的维度和原始权重 \(W_0\) 的维度是相同的,所以直接加到 \(W_0\) 上即可完成重参数化。这样额外的分支就合并到了原始的权重里,不会引入额外延迟。
到这里 LoRA 的微调过程就算介绍完了,下面再补充一些知识点和细节。
LoRA 降低了哪部分显存
我们知道使用 LoRA 可以大大减少微调的显存消耗量,然而 LoRA 相比原始模型是增加了模块,所以相比原始模型产生的梯度肯定是更大的。之所以能够降低显存,主要是因为 optimizer 中保存的 state 减少了,对于单层,从 \(d\times d\) 变为了 \(d\times r\),所以整体显存使用量依然是降低。
LoRA 加入模型的哪一部分
论文的作者将 LoRA 的作用范围限制在了 self-attention 的 projection 层中,也就是只有 QKV 和输出 O 的 projection 才使用 LoRA。在实验时,作者限制了可微调参数量,如果仅对 QKVO 中的一个使用 LoRA,则 rank 为 8;如果对其中两个使用,则 rank 为 4。
根据实验,相比于 rank 的大小,使用的 LoRA 数量对性能来说更重要。对所有的 QKVO 使用 LoRA 时,尽管 rank 很低(仅为 2),也能达到不错的效果。
LoRA 代码解读
其实主流的 LoRA 都是用 microsoft 的官方实现以及 huggingface 的
peft 库实现的,不过这类实现一般是用于
LLM,因为我们更关心如何在扩散模型里使用,所以这里基于
diffusers 的实现进行解读。
一些工程代码(可以略读)
首先还是先初始化了 stable diffusion 的各个模块:
1 | # Load scheduler, tokenizer and models. |
然后配置了一些 LoRA 的参数,可以看到设置了 r 和 \(\alpha\),以及初始化权重的方式和作用的 projection 范围:
1 | unet_lora_config = LoraConfig( |
然后把 LoRA 加入到 UNet 中:
1 | unet.add_adapter(unet_lora_config) |
这个 add_adapter 是由
diffusers.loaders.peft.PeftAdapterMixin 引入,这里调用了
peft 库里的 inject_adapter_in_model
方法,可以看到最后还是使用的 peft 中的实现。这个方法定义在
peft.mapping.inject_adapter_in_model,初始化了一个新的 peft
对象:
1 | tuner_cls = PEFT_TYPE_TO_TUNER_MAPPING[peft_config.peft_type] |
这里我们使用的是 lora,所以 tuner_cls 是
peft.tuners.lora.model.LoraModel。在这个对象初始化的时候,会调用
peft.tuners.tuners_utils.inject_adapter。核心的逻辑在这里,具体的看注释:
1 | # 获得模型所有模块的 key |
这里调用的 _create_and_replace 在 LoraModel
实现:
1 | def _create_and_replace(self, ...): |
具体怎么创建和替换不是很重要,只需要知道这里就是筛选了所有符合条件的 key 将其替换成了对应的 LoRA 模块即可。知道了替换的逻辑之后,下面我们看看 LoRA 模块内部的具体实现。
LoRA 的具体实现
在 peft 的 LoRA 实现中,提供了 Linear、Embedding、Conv2d
三种 LoRA 层,因为我们上边说的 LoRA 主要用在 self-attention 的
projection 中,所以重点分析一下 Linear 的实现。
LoRA 的初始化
Linear 的实现位于
peft.tuners.lora.layer.Linear,其继承自
nn.Module 和 LoraLayer,后者应该也可以看作一种
mixin。在初始化时,LoraLayer 初始化了以下属性:
1 | self.base_layer = base_layer # 这个就是没有加 LoRA 的 projection 层 |
然后在 update_layer 中进行了进一步的初始化:
1 | self.r[adapter_name] = r |
随后继续调用 reset_lora_parameters 初始化了权重:
1 | nn.init.normal_(self.lora_A[adapter_name].weight, std=1 / self.r[adapter_name]) |
推理过程实现
直接看 forward
函数的实现即可,具体的可以看下边代码里的注释。这里需要提前介绍一下,这个类有一个属性
merged
用来表示有没有重参数化过,如果已经进行了重参数化,那么这个属性就是
True,反之同理。
1 | def forward(self, x: torch.Tensor, *args: Any, **kwargs: Any) -> torch.Tensor: |
重参数化与反重参数化
重参数化就是把 base_layer 的权重 \(W_0\) 替换为 \(W_0+\Delta
W\),反重参数化则是需要进行这个过程的反过程。因此首先需要实现计算
\(\Delta W\),计算方式是 \(\Delta W=W_BW_A\),在代码中就是:
1 | def get_delta_weight(self, adapter) -> torch.Tensor: |
重参数化代码在 merge
中,这里也给出一个比较简化的版本,具体的见注释:
1 | def merge(self, safe_merge: bool = False, adapter_names: Optional[list[str]] = None) -> None: |
反重参数化也是同理:
1 | def unmerge(self) -> None: |
权重的保存和读取
可以看看 demo 里是怎么保存的 LoRA 权重:
1 | unwrapped_unet = unwrap_model(unet) |
从这段代码里可以看出,主要需要关注的就只有
get_peft_model_state_dict,这部分负责从模型的 state_dict
中将 LoRA 对应的权重提取出来。具体的为:
1 | def get_peft_model_state_dict( |
对于读取,则是直接使用 load_lora_weights:
1 | pipeline.load_lora_weights(args.output_dir) |
这部分的封装也是非常复杂,一直找到最内层是调用了
peft.utils.save_and_load 这个模块中的
set_peft_model_state_dict,简化一下大概是这样:
1 | def set_peft_model_state_dict( |
总结
感觉 LoRA 的思想还是很巧妙的,用很简单的方法实现了大模型的微调。虽然方法很简单,但是在工程实现方面由于很多中 peft 方法的实现,实际上还是很复杂的,真是很佩服写 peft 库的这群人,处理的情况也太多了,最后提供的接口也是很易用,tql。
参考资料: