笔记|扩散模型(一〇)Dreambooth 理论与实现|主题驱动生成
论文链接:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
项目主页:https://dreambooth.github.io/
非官方实现:huggingface/diffusers、XavierXiao/Dreambooth-Stable-Diffusion
时隔快两周继续更新一下 AIGC 系列的学习笔记,这篇文章算是比较火的一个工作,而且很多 AI 照相馆应用的背后也是这个算法。这一算法关注的任务是主题驱动生成,也就是给定某个特定物体(或者某个人或动物)的几张图像对模型进行微调,微调后就能生成该主题在各种场景、姿态下的图像。具体效果如下图所示,给出几张柯基的照片对模型进行微调,模型就能生成这只小狗的各种图像。

Dreambooth
Dreambooth 这个方法使用的依然是基础的文生图扩散模型,不过对这类模型进行了「个性化」。具体来说就是用给出的几张图像以及设计好的 prompt 对原始模型进行微调。微调的主要目的是把要生成的目标植入到输出 domain 中,这样在生成新图像时就可以从这个 domain 中查询出与其相关的新图像。
Prompt 设计
为了让模型知道要生成的是这个新主题的图像,作者设计了一种 prompt,也就是 "a [identifier] [noun]"。这里的 identifier 就表示要生成的新主题,noun 表示要生成物体的种类,例如这里就是 dog。在生成时,a dog 表示各种各样的狗狗,而 a [identifier] dog 就表示我们希望生成的这种狗狗。也就是说,通过微调,我们将 a [identifier] dog 这个文本与我们要生成的主题绑定到了一起。
对于 [identifier] 用词的选择,作者尝试了几种不同的方案。首先是使用 "rare"、"special" 这类词,用这类词的缺点在于模型在微调前就对这类词有一定的先验知识,让模型区分原有知识和我们提供的新形象是比较困难的,因此比较好的选择是使用一个比较稀有或者词表里不存在的词。一种比较直观的构造稀有词的方法是随机生成一串字母和数字的组合,比如 "xxy5syt00",然而这类词可能在 tokenize 之后就会变成一些常见的 token,这些 token 依然有比较强的先验,会导致和上述相同的问题。
因此作者实际的做法是去词汇表中寻找稀有的 token,然后将这些 token 转化为 text,得到对应的单词,例如一个常用的 identifier 是 sks。(不过最近也有人反对使用这个词,因为 SKS 是一种半自动步枪的型号,可能也会对模型产生误导)
类别先验保持损失
在微调时我们只使用了一种 prompt 和少量的几张图片,这样会导致模型对普通 dog 类别的生成能力退化,产生过拟合。具体来说,这种过拟合会导致两种不利结果:
- Language Drift:这是在文本模型微调时会出现的一种现象,使用少量文本对模型进行微调时,会导致模型忘记原有的语义信息。在这里也就是模型忘记了如何生成其他狗的图片,只能生成这一种狗。
- 输出多样性降低:这个也是过拟合到一种狗狗导致的结果,尽管我们也只是想生成柯基这一种狗狗,但是生成的过程实际上是依赖于原始模型对各种狗的先验的。忘记原有先验会导致生成的柯基的多样性降低。
为了保持模型原有的类别先验,作者提出了一种新的损失,用模型在微调前自己生成的样本来监督微调过程。这种损失表示为: \[ \mathbb{E}_{\mathbf{x},\mathbf{c},\epsilon,\epsilon',t}[w_t||\hat{\mathbf{x}}_\theta(\alpha_t\mathbf{x}+\sigma_t\epsilon,\mathbf{c})-\mathbf{x}||_2^2+\lambda w_{t'}||\hat{\mathbf{x}}_\theta(\alpha_{t'}\mathbf{x}_\mathrm{pr}+\sigma_{t'}\epsilon',\mathbf{c}_\mathrm{pr})-\mathbf{x}_\mathrm{pr}||_2^2] \] 第一项就是普通的损失,第二项中的 \(\mathbf{x}\) 都变成了 \(\mathbf{x}_\mathrm{pr}\),表示提前生成的图像。
训练与采样过程
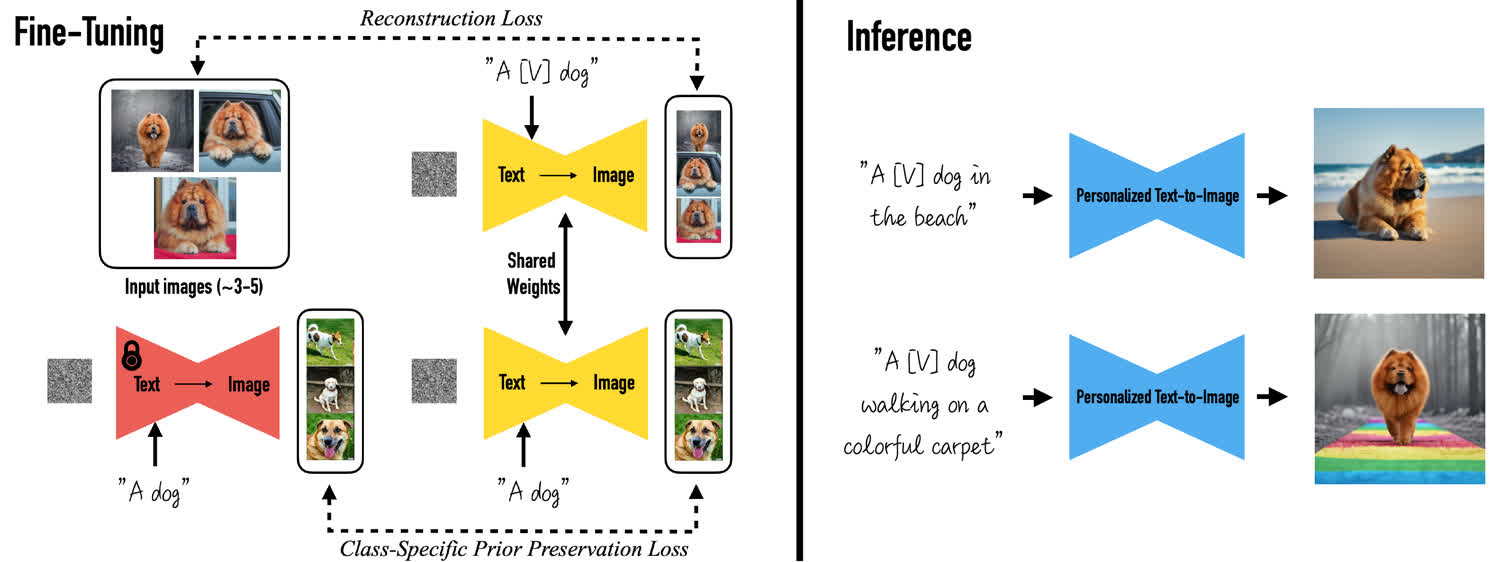
具体的训练和采样过程如下所示,给定几张狮子狗的照片进行微调,先用 "a dog" 作为 prompt 生成一部分图像,这部分图像在微调过程中用来计算先验保留损失,然后用 "a [V] dog" 微调生成狮子狗的过程,这部分直接计算重建损失。在采样过程中,直接用 "a [V] dog" 表示这只狮子狗即可生成各种场景下的狮子狗。
Dreambooth 代码解读
这里参考的是 diffusers 提供的 dreambooth
训练代码,工程上的内容就忽略了,这里只关注主要逻辑。
首先观察一下基础模型用的是什么:
1 | tokenizer = AutoTokenizer.from_pretrained( |
可以看到这里用的是 DDPMScheduler 和
UNet2DConditionModel,可以看出用的就是最普通的
DDPM。实际上在原论文中也提到了,一开始生成的是 64
分辨率大小的图像,后来再超分辨率到 1024
大小。(当然这个脚本也选择性地加载了 VAE,所以也可以使用 Stable
Diffusion)
然后我们来看数据部分,脚本中定义了一个
DreamBoothDataset:
1 | class DreamBoothDataset(Dataset): |
从后边的 __getitem__
可以看出,这个数据集可以传入两组图片路径和
prompt,instance_data_root
就是我们微调用的柯基的图片路径,instance_prompt 就是 "a [V]
dog"。除此之外还可以传入另一组,class_data_root
就是原模型预先生成的图像,class_prompt 就是 "a
dog"。这两组在 __getitem__ 中分别被读取并
embed,最后分别存入 instance_xxx 和 class_xxx
的两组字段中。
在 training loop 中,主要关注这几个部分:
1 | prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean") |
可以看到在训练时分别计算了普通的重建损失,以及先验损失,并在最后进行了加权。
总结
Dreambooth 作为一种少样本微调的方法还是很有效的,不过这种方法也有一些缺点,例如微调实际上依赖于模型对目标类别的先验,如果基础模型就不了解这种对象,可能就无法生成。例如如果我想生成一个奇怪的物体,基础模型没有在类似的数据上训练过,就无法生成。除此之外在某些特定 IP 的生成上,dreambooth 也表现得不是特别好。
参考资料: