笔记|扩散模型(九)Imagen 理论与实现
论文链接:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Imagen 是 Google Research 的文生图工作,这个工作并没有沿用 Stable Diffusion 的架构,而是级联了一系列普通的 DDPM 模型。其主要的贡献有以下几个方面:
- 使用比较大的文本模型进行文本嵌入,可以获得比使用 CLIP 更好的文本理解能力;
- 在采样阶段引入了一种动态阈值的方法,可以利用更高的 guidance scale 来生成更真实、细节更丰富的图像(这里的阈值是控制 \(\mathbf{x}\) 的范围);
- 改良了 UNet,提出 Efficient UNet,使模型更简单、收敛更快、内存消耗更少。
该模型的架构如下图所示,可以看到使用了一个条件生成的 diffusion 模型以及两个超分辨率模型,每个模型都以文本模型的 embedding 作为条件,先生成一个 64 分辨率的图像,然后逐步超分辨率到 1024 大小。
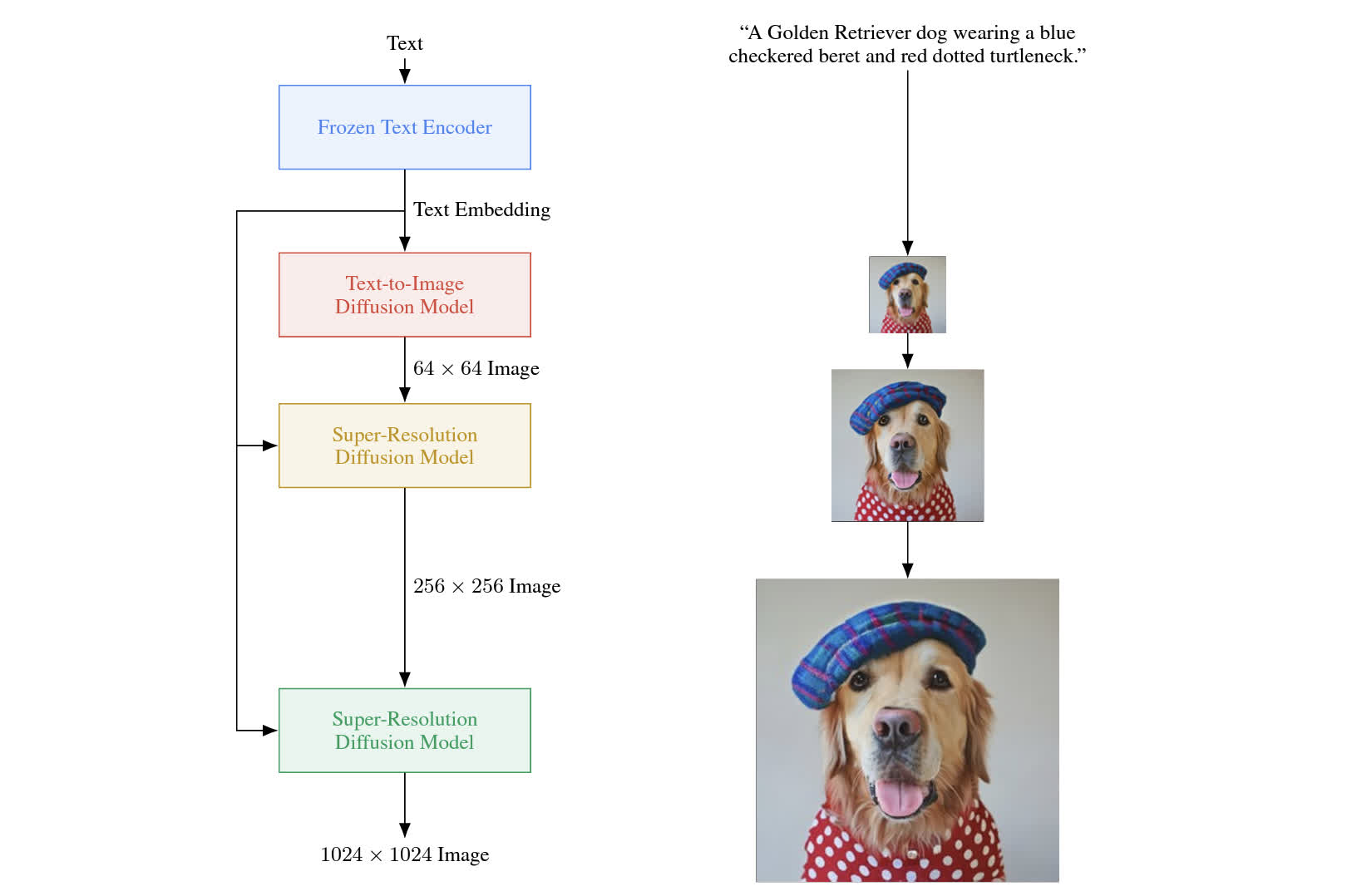
Imagen
预训练文本模型
现在的文生图模型主流使用的文本嵌入方法是使用 CLIP 文本编码器,在直观上感觉是比较合理的,因为 CLIP 的文本特征和图像特征共享同一个空间,用来控制图像的生成过程是比较合理的。不过 CLIP 的缺点是对文本的表达能力比较有限,处理复杂文本比较困难。
这里选择的不是使用 CLIP,而是使用规模比较大、且在大规模文本语料上训练的文本模型,具体来说使用的模型有 BERT、T5 和 CLIP。经过实验(具体结果可以看原论文 Figure 4 的 a 和 b,以及 Figure A.5),主要有以下发现:
- 缩放文本编码器对提升生成质量的作用很明显;
- 相比增大 UNet 的尺寸,增大文本编码器的尺寸更重要;
- 相比于 CLIP,人类更偏好 T5-XXL 的结果。
高 Guidance Scale 的改善
提高 classifier-free guidance 的 guidance scale 可以提升文本-图像的匹配程度,但是会破坏图像的质量。这个现象是因为高 guidance scale 会导致训练阶段和测试阶段出现 mismatch。具体来说,在训练时,所有的 \(\mathbf{x}\) 都分布在 \([-1,1]\) 的范围里,然而当使用比较大的 guidance scale 时,得到的 \(\mathbf{x}\) 会超出这个范围。这样会导致 \(\mathbf{x}\) 落在已经学习过的范围以外,为了解决这个问题,作者研究了静态阈值(static thresholding)和动态阈值(dynamic thresholding)两种方案,具体算法如下图所示:

静态阈值
这种方法就是在预测噪声后,先计算出 \(\mathbf{x}_0\),然后将其取值范围直接裁剪到 \([-1,1]\) 之间,然后再进行去噪。这种方法已经很多方法都使用了,例如 openai/guided-diffusion 中的这段代码就是为了进行这种处理:
1 | def process_xstart(x): |
动态阈值
这个方法不是很好理解,我们可以从一个例子出发,我们平时进行 classifier-free guidance 时使用的 guidance scale 通常都是 7.5,那么一个原本分布在 \([-1,1]\) 之间的变量乘以这个系数之后就会变到 \([-7.5,7.5]\) 的范围内。如果某处的几个数分别是 \(\{0.2, 0.4, 0.6, 0.8\}\),乘以 7.5 后就变成了 \(\{1.5,3.0,4.5,6.0\}\)。如果此时直接将这些数裁剪到 \([-1,1]\),那么所有的数都会变成 1,原本这些数之间是有比较大的差别的,裁剪后都变成了相同的数,这样很明显是不合理的,动态阈值就是为了寻找一个比较合理的裁剪范围。
这里的做法是寻找一个 \(\mathbf{x}_0\) 的 p-分位数 \(s\),也就是找到大多数的数字落在什么范围内,然后先裁剪到 \([-s,s]\) 范围内,再全部除以 \(s\) 以缩放到 \([-1,1]\) 的范围内。实验发现这种方法能比较好地改善图像的质量,这部分的代码如下所示(摘自非官方实现):
1 | if pred_objective == 'noise': |
级联扩散模型
为了生成高分辨率图像,模型级联了三个扩散模型,一个用来生成低分辨率图像,两个用来将低分辨率图像逐步超分到高分辨率。在训练阶段,作者发现使用带有噪声条件增强的超分模型可以生成更高质量的模型。具体来说,每次生成噪声时,还从 \([0,1]\) 范围内随机采样一个 aug level,然后基于这个 level 进行增强。在预测噪声时,不仅输入带噪声的图像、低分辨率图像、时间步,还输入一个 aug level。在推理阶段,使用一系列 aug level 进行增强,然后分别进行推理,从中选取一个最佳样本,这样可以提升采样效果。具体的算法如下所示:

总结
除了上述的一些贡献,Imagen 还做了一些工程上的改进,例如使用了不同的 text condition 注入方式,以及对基础的 UNet 模型进行了改进,提出了 Efficient UNet 模型等。相比同期的其他方法,Imagen 应该是为数不多可以直接生成 1024 分辨率图像的 diffusion 模型,虽然和主流的 Stable Diffusion 架构不同,但其中的一些改进思路还是值得学习一下的。