笔记|扩散模型(六)DALL-E 理论与实现|自回归文生图
论文链接:Zero-Shot Text-to-Image Generation
官方实现:openai/DALL-E
虽然 DALL-E 并不是基于扩散模型的方法,但是因为它的后续工作 DALL-E 2 和 DALL-E 3 都是基于扩散模型的,所以这个方法也放到扩散模型系列里。
DALL-E 是 OpenAI 比较早期的文生图模型,和一些早期的多模态方法的做法类似,其主要的思想是将图像的 token 和文本的 token 当作同一个序列输入 Transformer,利用自回归生成能力进行图像生成。除了使用 Transformer 进行生成之外,由于图像的像素数量相比文本 token 来说过多,因此需要将图像也预先进行 tokenization,这里使用的模型是 VQ-VAE(也就是 dVAE);为了优先输出生成质量比较高的结果,这里使用 CLIP 对结果的质量进行了排序。总结来说,DALL-E 共包括三个部分:
- Transformer:用来进行自回归生成;
- VQ-VAE:将图像 tokenize 压缩后得到图像 token,再输入 Transformer;
- CLIP:对生成的结果进行评分与排序。
DALL-E 的训练和推理
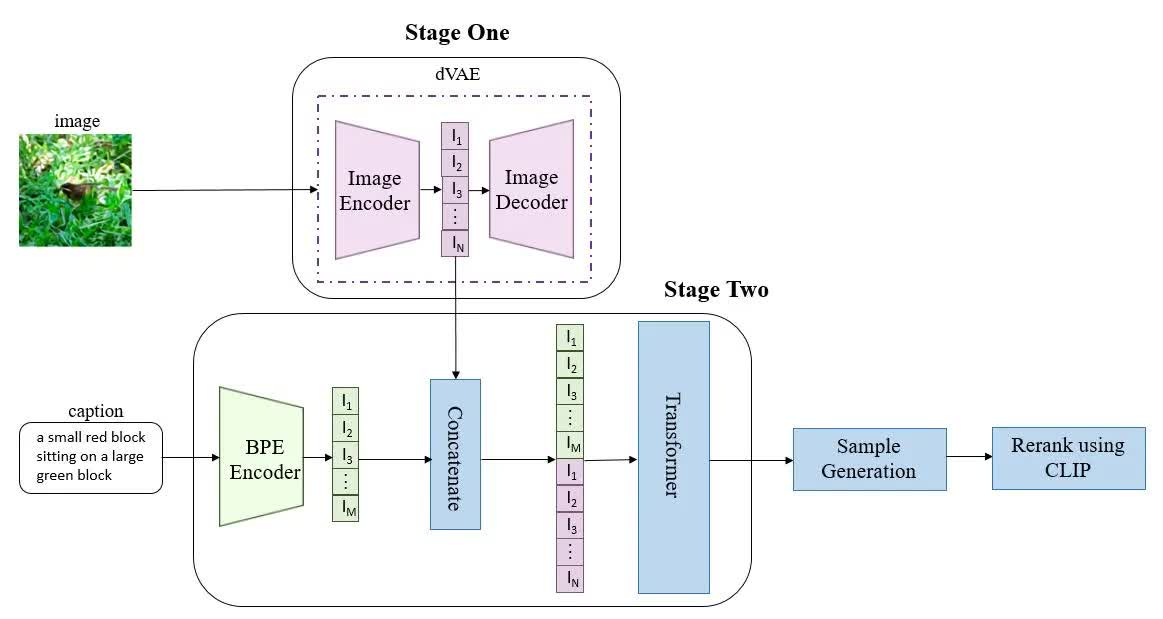
DALL-E 的整体结构如上图所示,图中的几个部分都是单独进行训练的。这里分别对 DALL-E 的训练和推理过程进行介绍,首先是训练过程。训练分为两个阶段,第一个阶段训练 VQ-VAE 的 codebook,第二阶段训练 Transformer,分别对应于上图中标注出的 Stage One 和 Stage Two。
训练第一阶段:训练 VQ-VAE。VQ-VAE 是一种隐空间离散化的 VAE,其隐空间由一个大小为 \(8192\times C\) 的可学习 codebook 组成,也就是说每个隐变量在隐空间中只有 8192 种可能的取值,每个取值是一个长度为 \(C\) 的特征。通过使用 VQ-VAE,可以将一张大小为 \(256\times256\) 像素的 RGB 图像压缩到 \(32\times32\) 个 token,也就是 VQ-VAE encoder 的输出是一个大小为 \(32\times32\times8192\) 的变量,再用 codebook 进行索引得到 \(32\times32\times C\) 大小的图像 token,也就是共有 1024 个图像 token。
训练第二阶段:训练 Transformer。首先用 BPE(byte-pair encoding)将文本 tokenize,得到最多 256 个文本的 token,如果文本 token 数不足 256 则进行 padding。最终得到的 256 个文本 token 与 VQ-VAE 得到的 1024 个图像 token 拼接成一个长度为 1280 的序列,然后进行自回归训练。
推理分为两种情况:(1)纯文本生成图像;(2)文本+图像生成图像。这两种情况的区别就在于使不使用图像的 token,如果不使用图像的 token,那么 Transformer 的输入就是 256 个文本 token;如果使用图像的 token,那么 Transformer 的输入就是 256 个文本 token+1024 个图像 token。
在推理阶段,Transformer 的输出也是图像的 token,这些图像的 token 首先和 VQ-VAE codebook 中的隐变量进行匹配,然后再使用 VQ-VAE 的 decoder 进行解码得到最终生成的图像。生成图像后,所有的图像和文本分别被输入到 CLIP 的图像编码器和文本编码器,得到的编码结果再计算匹配分数,即可用来评价生成效果。最终所有生成的图像按匹配分数进行排列后输出,即得到最终的推理结果。
除了基本的训练和推理之外,文章的附录中还包括了一些更详细的介绍,例如对 VQ-VAE 的特殊处理、Transformer 中使用的 attention 的介绍以及数据收集方式和训练方法等。对进一步细节感兴趣的读者可以参考原论文了解这些内容。
代码实现解读
这里参考的是上面的lucidrains/DALLE-pytorch,代码质量更高一点,主要关注一下推理部分的代码。推理部分的代码在
dalle_pytorch/dalle_pytorch.py 的
DALLE.generate_images。
首先是采样函数的定义,可以看到采样时不仅可以使用文本作为条件,也可以加入图像作为条件:
1 |
|
然后初始化了文本的 token,并且对文本的 token 做了截断,截断到最长为 256 个 token:
1 | text = text[:, :text_seq_len] # 这里的 text_seq_len=256 |
当存在图像作为输入时,将图像也进行 tokenize,首先用 VQ-VAE 编码,然后把编码后的结果拼接到文本后方:
1 | if exists(img): |
然后使用 Transformer 进行自回归生成:
1 | prev_cache = None |
将生成的图像 token 使用 VQ-VAE 的 decoder 转换为最终生成的图像:
1 | images = vae.decode(img_seq) |
最后如果使用 CLIP,则计算文本与图像之间的匹配分数,否则直接返回结果:
1 | if exists(clip): |
总结
虽然 DALL-E 并不是基于扩散模型的,但是作为一个 2021 年初的方法,这个方法还是很有前瞻性的:首先,这个方法是基于自回归的,虽然后续的 diffusion model 不再基于这一范式,但是最近出现的 VAR 模型又回归了这种生成方式。而且这和 OpenAI 一直遵循的 scaling-law 是一脉相承的,相比于普通的 diffusion 架构,Transformer 架构更易于 scaling,生成效果也能从中受益。另一个有前瞻性的点在于 DALL-E 尝试性地将 CLIP 应用在文生图任务中,这也是后续的文生图模型都遵循的一个方法。(虽然在这个工作中 CLIP 的地位并不重要)