技术相关|使用 Pytorch 进行分布式训练
其实 Pytorch 分布式训练已经不算什么新技术了,之所以专门写一篇 blog 是因为今天训模型的时候出现了一个没见过的问题,在调试的时候发现自己平时都是用别人写好的分布式代码,没有深入研究过其中的实现细节,因此感觉有必要整理吸收一下。
最简单的数据并行
作为最简单的并行计算方式,使用 nn.DataParallel
只需要添加一行代码即可完成:
1 | module = nn.DataParallel( |
除此之外,其他的部分和单卡训练的内容基本上都相同。在使用
nn.DataParallel
进行训练时,在每次前向传播时,nn.DataParallel
会做以下几件事:
- 切分数据:对于输入的 Tensor,其会被沿 batch 维度切分成多份,用于输入不同的显卡;对于元组、列表、字典等类型,其会被浅拷贝后用于输入;对于其他类型,在显卡之间是直接共享的。
- 拷贝模型:为了保证模型参数在显卡间保持一致,将模型拷贝到每一张显卡上。
- 并行计算:每张显卡分别对各自的数据执行前向传播。
- 汇总输出:将所有显卡的前向输出汇总到
output_device对应的设备上。
模型和数据都需要预先加载到 GPU 中,否则可能会产生错误。
虽然非常方便,但 nn.DataParallel
的缺点也是显而易见的:尽管前向传播的计算过程已经实现了并行,但由于程序依然通过单个进程控制,其他的部分(例如数据加载等)依然为串行进行,无法有效利用
CPU
的多核性能。同时,大量的设备间数据拷贝也会带来很大的性能损失。除此之外,由于需要将输出汇总到单个设备上,这也引入了设备间负载不均衡的问题。
因此,从效率的角度上来说,nn.DataParallel
并不是一个很好的解决方案,通常我们进行并行训练应该优先使用分布式的方案,也就是下一节会讲到的
torch.distributed 模块。
分布式数据并行
顾名思义,分布式数据并行不再以单个进程来控制训练流程,而是为每一张 GPU 都单独分配一个进程,每个进程之间的训练流程彼此独立,仅仅在一部分流程中(例如梯度计算、参数更新等)才需要进行进程间同步,这很好地解决了上一节最后提到的问题,效率更高。
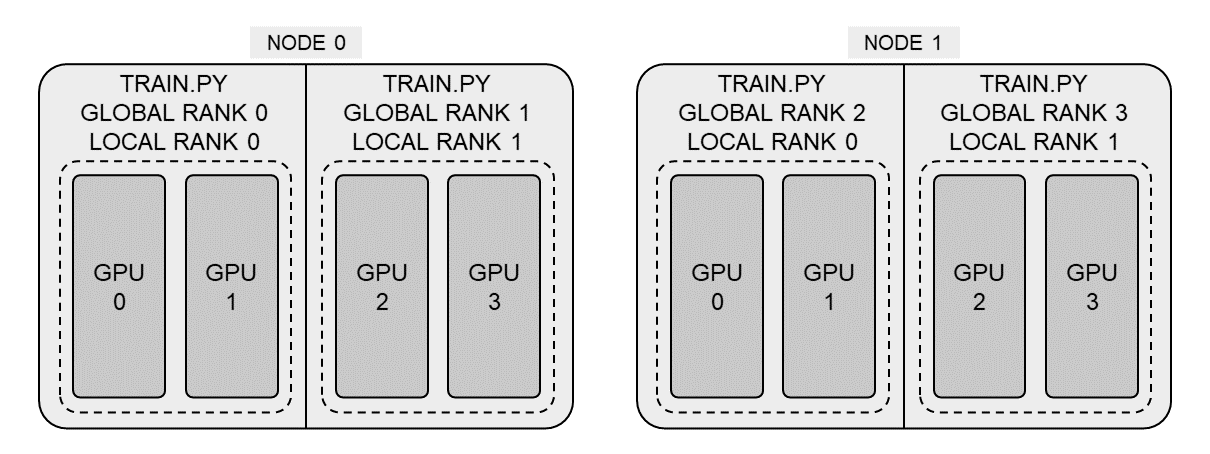
在正式开始介绍之前有以下几个概念需要简单介绍一下。如下图所示,分布式训练可以分为节点(node)和进程(worker)两个层次,下图中有两个节点,每个节点内又有两个进程,每个进程使用了两张显卡。节点可以简单地理解成一台服务器(无论是一个虚拟机还是一台物理机),每个进程都是使用
pytorch 分布式启动器从 train.py
创建出来的。为了标识不同的进程(以便进程内部选择使用哪块显卡、设置种子等操作),每个进程又有一个本地序列号(local
rank)和全局序列号(global rank)。
Pytorch 的分布式训练是通过一个形如 torchrun train.py
的命令启动的,torchrun 是 Pytorch 封装的启动工具,它会
spawn 多个进程分别用于运行 train.py,且在创建进程时,会将
local rank、world size 等进程所需的值用命令行参数的形式传递给进程。
基于以上的流程,我们需要做的第一件事就是接收传递的参数:
1 | parser = argparse.ArgumentParser() |
随后初始化 GPU 之间通信使用的后端,并限定进程使用的 CUDA 设备:
1 | import torch.distributed as dist |
为了防止不同进程中使用的数据完全相同导致训练退化,还需要用
DistributedSampler 对数据的顺序进行打乱:
1 | from torch.utils.data.distributed import DistributedSampler |
最后使用 DistribuedDataParallel 包装模型:
1 | from torch.nn.parallel import DistributedDataParallel |
其他的部分就基本上和普通的训练代码一样了。在启动的时候也比较特殊,不是直接运行
python train.py,而是需要使用启动工具:
1 | torchrun \ |
多机多卡训练
实际上多机多卡训练和单机多卡训练并没有本质上的区别,无论不同进程间在同一个节点还是在不同的节点,分布式训练本质上就是进程间通过一定的通信方式,将梯度进行汇总并用来更新每一个进程中的模型参数。不过和单机多卡不同的是,不同的节点之间需要知道用何种 IP 地址与端口号进行通信,因此相比于单机多卡,需要额外指定这两个参数。
假设我们使用的 master node 的 IP 为
115.116.117.118,端口号为
29500,共有两个节点,那么我们只需要在两个节点上分别运行以下命令即可:
1 | Node 0 |
使用 Slurm 管理多机多卡训练
对于一般的用户来说,上述的多机多卡训练方式已经基本上够用了。然而对于需要进行更大规模训练的人来说,在每个节点上依次运行命令比较繁琐并且容易出错。同时,大规模 GPU 集群需要有效的管理方式,来提高资源利用率。为了做到这一点,Slurm 是一个比较好的选择。Slurm 主要的作用在于任务调度,其可以为用户分配计算机节点来执行任务,并且支持任务队列,可以比较高效地分配资源。
在编写训练脚本时,无论启动方式如何,我们关心的都是 master
节点地址、local rank、进程总数等信息,我们可以参考 mmcv
的方式对这些内容进行初始化:
1 | def _init_dist_slurm(backend: str, port: Optional[int] = None) -> None: |
在任务启动时,使用 Slurm 提供的工具:
1 | srun \ |
Pytorch 版本兼容
Pytorch 的分布式训练经历了一些迭代,启动分布式训练的方式也发生过一些变化,以下是不同版本间主要的区别:
Pytorch 版本低于
2.0时:torchrun在传递参数时,不同的单词并非用 dash 连接,而是使用下划线,例如:torchrun --nproc_per_node=8 --nnodes=1 train.py。Pytorch 版本低于
1.10时:不支持torchrun,而应该使用类似如下的方式启动:1
2
3
4python -m torch.distributed.launch \
--nproc_per_node=8 \
--nnodes=1 \
--use_env train.py可以发现和
torchrun的用法基本上是一样的,只是需要在脚本路径前加上--use_env。
参考资料: